






Chinese-Vicuna:低资源下的中文对话与指令模型
在单个GPU上进行高效训练与部署的中文LLaMA模型
直达下载
返回上一页
描述
在单个GPU上进行的Chinese-Vicuna项目,该项目提供了一种高效的中文LLaMA模型训练方法,适合低资源环境下的部署和应用。
介绍
Chinese-Vicuna旨在构建和共享一种能够在单个Nvidia RTX-2080TI上训练的中文LLaMA模型调优方法。此模型特别适合需要指令跟随能力的应用场景,例如多轮对话机器人,该机器人可以在单个Nvidia RTX-3090上使用2048长度的上下文进行训练。
为何命名为“小羊驼”(Vicuna):
鉴于小羊驼、羊驼等动物命名的成功,开发者希望训练一个类似Vicuna的中文小羊驼——体积小但足够强大!

解决方案的优势:
- 高参数效率:在较低资源的GPU上即可完成模型的指令调优。
- 显卡友好:适配性广,能够在2080Ti及3090显卡上进行有效训练。
- 易于部署:支持多GPU推理,进一步减少VRAM的占用,简化部署过程。
项目内容包括:
- 模型微调的代码
- 基于训练模型的生成代码
- CPU上运行的代码(支持fp16或int4)
- 工具下载/转换/量化原始facebook llama.ckpt的工具
多轮指令演示和互动:
提供了基于beam-size为4的指令演示,展示了同时进行的四个过程的输出。
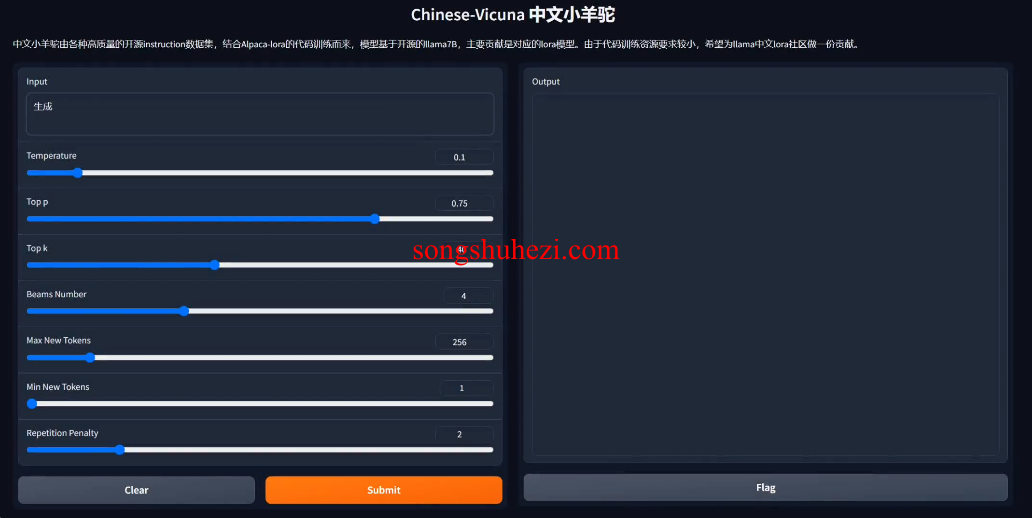
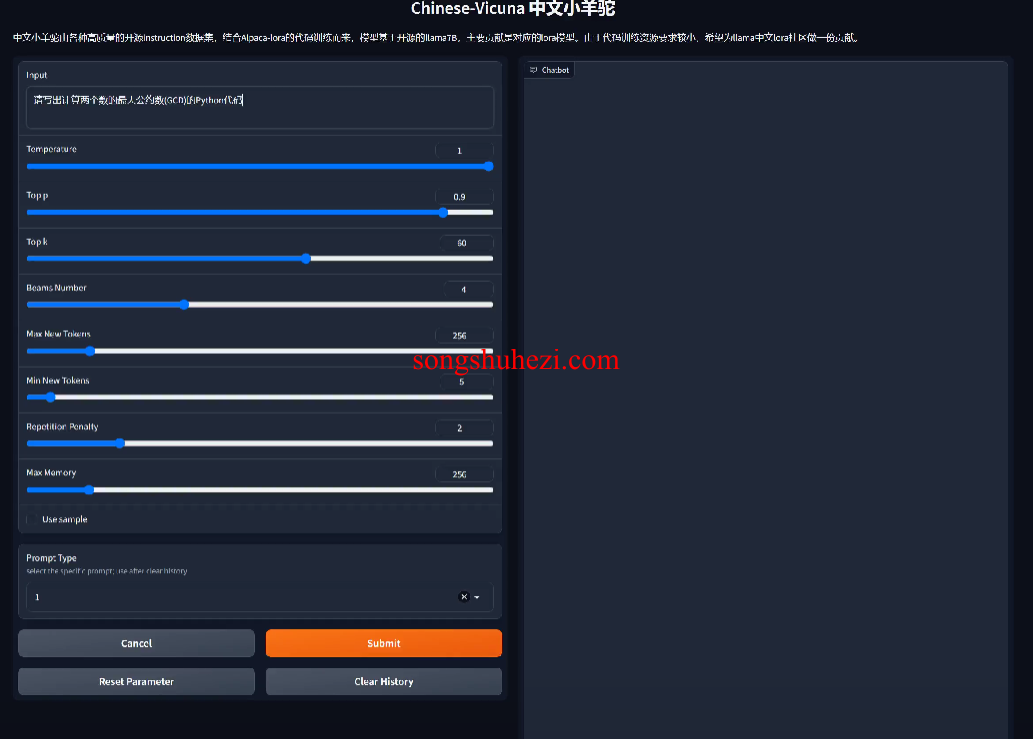
Chinese-Vicuna不仅使中文LLaMA模型的训练变得更加可达性强和成本效益高,还通过提供一个完整的解决方案框架,极大地促进了技术的应用和普及。尤其是它在低资源GPU上的表现优势,为中小企业甚至个人开发者打开了使用大型语言模型的大门,这在我看来是一个巨大的技术推动。通过简单的设备配置就能实现高效的模型训练和推理,这在很大程度上降低了进入门槛,使得更多的创新者能够参与到AI模型开发的浪潮中来。
×
直达下载
反爬虫抓取,人机验证,请输入验证码查看内容
请扫描上方公众号二维码,发送关键字:2024,获取验证码。
微信搜索公众号:“程序员老鬼”或者“chatgpt1499” 或微信扫描右侧二维码关注微信公众号





类别
×
初次访问:反爬虫,人机识别
反爬虫抓取,人机验证,请输入验证码查看内容
请关注本站公众号回复关键字:“2024”,获取验证码。
微信搜索公众号:“程序员老鬼”或者“chatgpt1499” 或微信扫描右侧二维码关注微信公众号


 RSS
RSS
