






V-JEPA:由Meta AI研究团队开发的一种自监督学习方法
专门用于从视频中学习视觉表示
最近,我在网络上偶然发现了一个名为V-JEPA的项目,这是Meta AI研究团队推出的一个自监督学习方法,专门用于从视频中学习视觉表示。我对它的独特之处非常好奇,决定深入研究。
V-JEPA简介
V-JEPA,全称为Video Joint-Embedding Predictive Architecture,即视频联合嵌入预测架构。这个模型通过观看视频来学习理解物理世界,无需人工标注或其他形式的外部监督。
它通过预测视频中的特征表示来训练自己,这个过程完全基于视频内容本身,旨在捕捉视频中的时间连续性和空间结构。我发现这种方法非常有趣,因为它不是简单地重建像素,而是在更高层次上理解视频内容。
V-JEPA的工作原理
V-JEPA的预训练完全基于一种无监督的特征预测目标。与生成方法(有像素解码器)不同,V-JEPA拥有一个预测器,在潜在空间中进行预测。
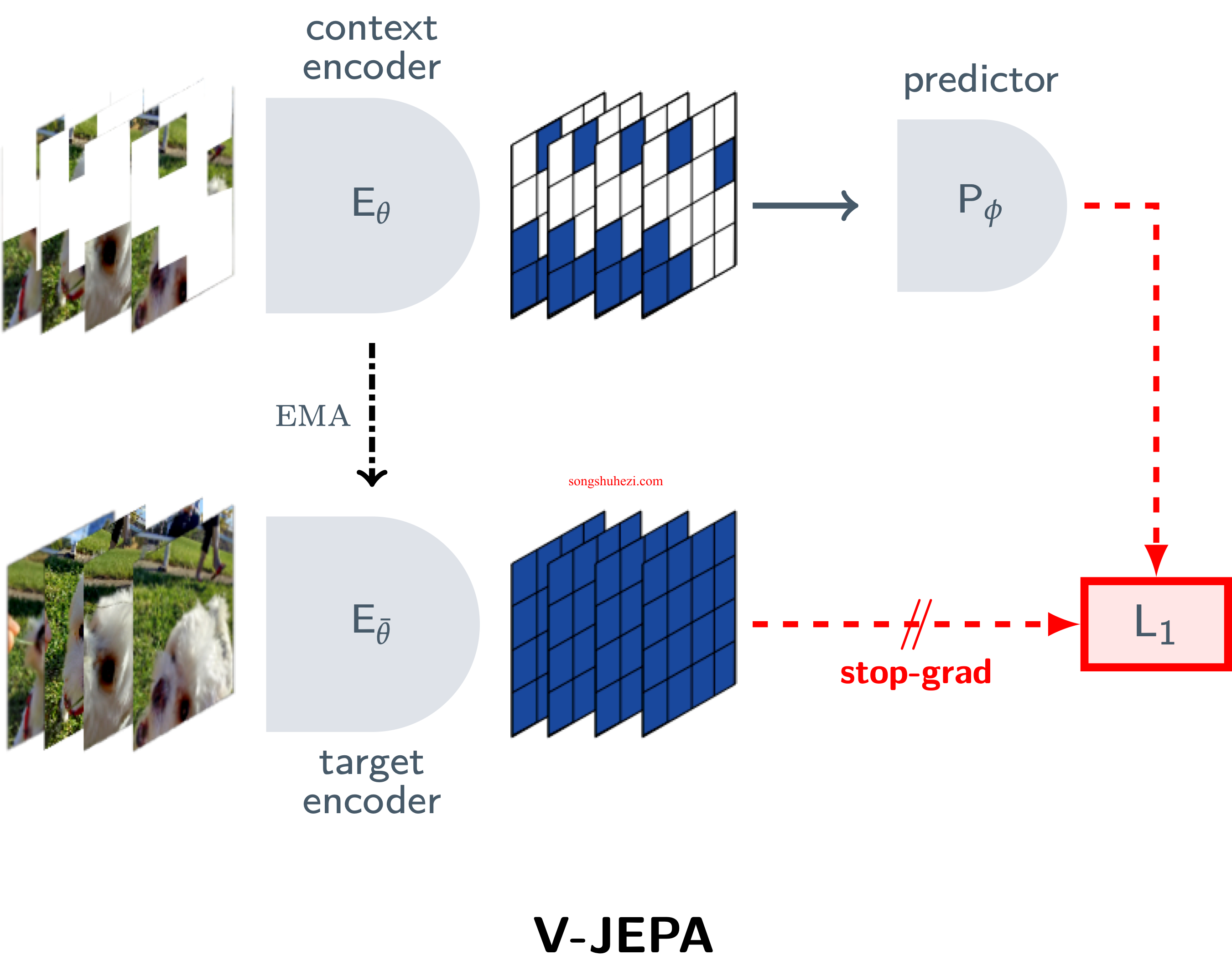
通过训练一个条件扩散模型将V-JEPA的特征空间预测解码为可解释的像素,而预训练的V-JEPA编码器和预测网络在此过程中保持冻结。
解码器只被赋予视频中缺失区域的预测表示,而无法访问视频的未掩盖区域。V-JEPA的特征预测确实是有根据的,并且与视频的未掩盖区域在时空上保持一致。





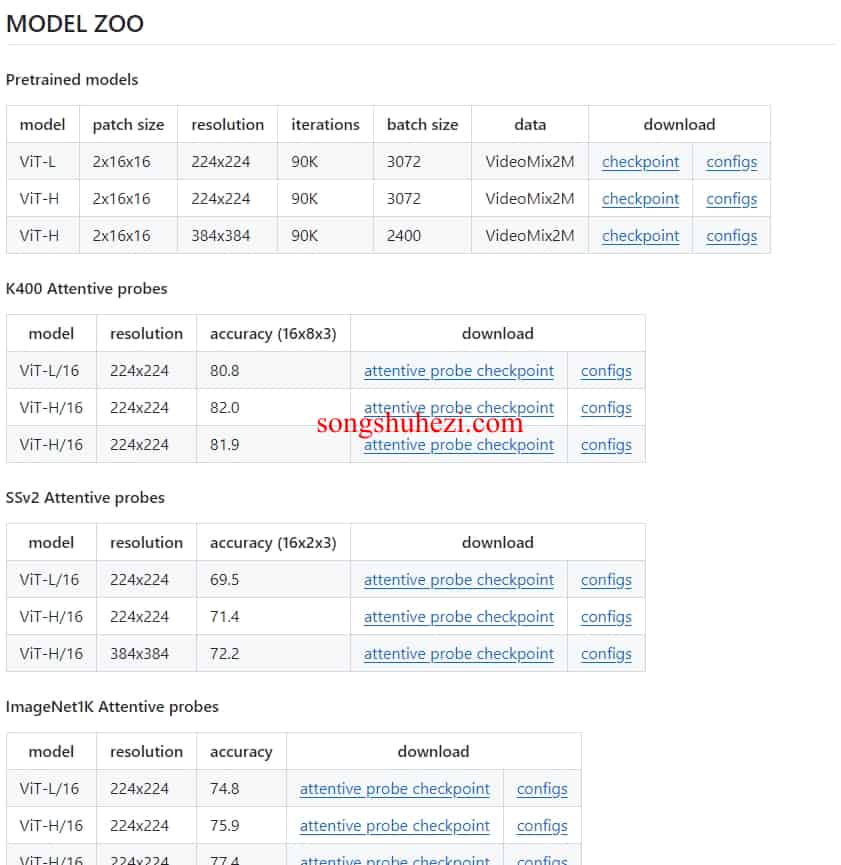
模型库
V-JEPA提供了多种预训练模型,包括不同分辨率和配置的ViT-L和ViT-H模型,以及在VideoMix2M数据集上进行训练的检查点。
使用方法
V-JEPA的官方PyTorch代码库提供了全面的使用说明,包括数据准备、模型预训练、评估和微调的指南。所有实验参数都在配置文件中指定,这些配置文件提供了训练和评估的详细指南。
例如,要在本地或分布式系统上启动V-JEPA预训练,用户需要根据自己的目录更新配置文件中的路径,指明日志、检查点的保存位置和训练数据的位置。
实验结果
V-JEPA在多个标准视频和图像任务上达到了令人印象深刻的性能,包括Kinetics-400动作识别、Something-Something V2动作分类和ImageNet图像分类。这证明了V-JEPA通过视频观察学习到的视觉表示的有效性和多功能性。
V-JEPA代表了视频自监督学习领域的一个重要进步,它通过预测视频中的特征表示来学习丰富的视觉知识。这种方法不仅在理论上具有创新性,而且在实际应用中展现了强大的性能,尤其是在有限的标注数据下表现出的高效和鲁棒性。随着自监督学习领域的不断进展,V-JEPA及其未来的改进版本有望在视频理解和其他视觉任务上发挥更大的作用。

反爬虫抓取,人机验证,请输入验证码查看内容
请扫描上方公众号二维码,发送关键字:2024,获取验证码。
微信搜索公众号:“程序员老鬼”或者“chatgpt1499” 或微信扫描右侧二维码关注微信公众号






反爬虫抓取,人机验证,请输入验证码查看内容
请关注本站公众号回复关键字:“2024”,获取验证码。
微信搜索公众号:“程序员老鬼”或者“chatgpt1499” 或微信扫描右侧二维码关注微信公众号


 RSS
RSS