






Ollama:在本地运行Llama2、Gemma等多种大模型
轻松在本地运行Llama2、Gemma等多种大模型,无需GPU
直达下载
返回上一页
描述
Ollama,一个能够在本地轻松运行Llama2、Gemma等大模型的框架,突出了其简易安装、多模型支持和丰富生态等特点。
介绍
一个让你能在家里悠哉悠哉运行Llama2、Gemma这类大模型的项目,是不是听着就很有意思?这个项目不但让你不用GPU,连上网都不需要,纯纯的神器啊!
Ollama——一个简明易用的本地大模型运行框架。随着围绕着 Ollama 的生态走向前台,更多用户也可以方便地在自己电脑上玩转大模型了。

特点
Ollama有什么特点:
- 只要你有个电脑,就能跑,不管你是用的CPU还是啥,家用电脑轻松应对。
- 安装简直不能再简单,Windows、Linux、Mac全都不在话下。
- 支持的大模型不只一两个,Llama 2、Gemma、通义千问、还有LLaVA(专门搞图片识别的)等等,应有尽有。
- 告别复杂设置,提供REST API服务,方便得很。
- 生态系统丰富,围绕这个项目,已经衍生出各种web界面、桌面软件、SDK库,丰富你的选择。
快速上手
接下来,简单几步,教你怎么玩转本地大模型
步骤1:安装与运行大模型
GitHub上找到项目,下载自己需要的版本。
装好后,打开命令行,一行命令就行:
ollama run llama2
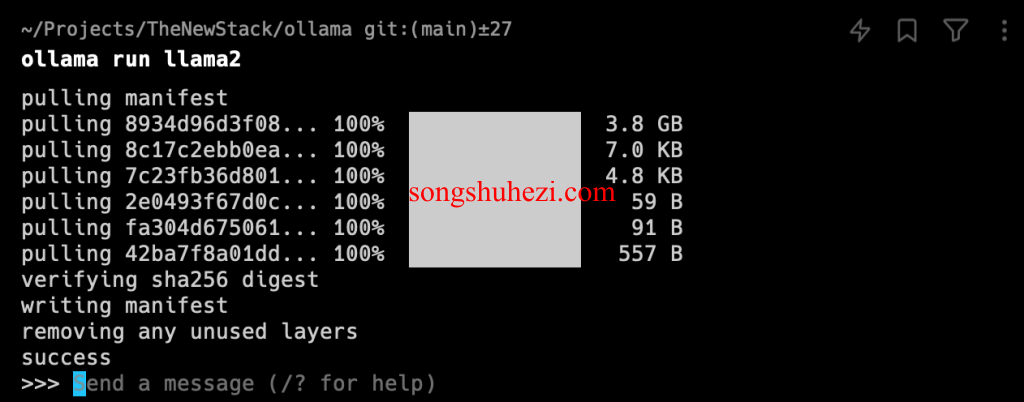
运行起来,界面一出现,你就成功了。
步骤2:部署web界面
喜欢ChatGPT界面?输入下面这条命令,一键部署一个类似的web界面:
docker run -p 3000:3000 ghcr.io/ivanfioravanti/chatbot-ollama:main
部署成功后,打开浏览器访问http://localhost:3000,你的私有GPT就成功了,重点是,完全离线使用。
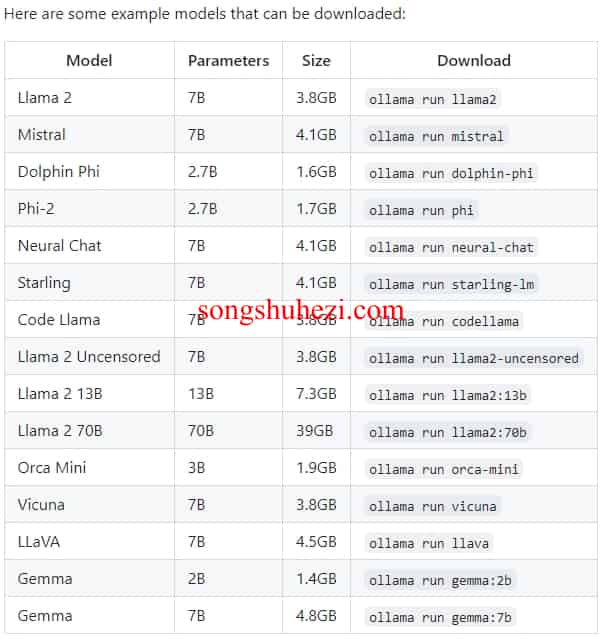
内存是关键
各种模型任你挑,但别忘了,内存够不够是关键。不同模型,内存需求不同,要根据你的机器配置来选择合适的模型。
回望过去,开源大模型领域风起云涌,Meta推出的Llama 2就像一股清流,给开源社区带来新的生机。而如今,谁还说LLM就是昂贵的GPU?本地大模型让大家都能享受到AI的魅力。
×
直达下载
反爬虫抓取,人机验证,请输入验证码查看内容
请扫描上方公众号二维码,发送关键字:2024,获取验证码。
微信搜索公众号:“程序员老鬼”或者“chatgpt1499” 或微信扫描右侧二维码关注微信公众号





类别
×
初次访问:反爬虫,人机识别
反爬虫抓取,人机验证,请输入验证码查看内容
请关注本站公众号回复关键字:“2024”,获取验证码。
微信搜索公众号:“程序员老鬼”或者“chatgpt1499” 或微信扫描右侧二维码关注微信公众号


 RSS
RSS