






Whisper:把视频和语音文件转换成文字
openai开源免费部署自己的语音识别系统
最近,OpenAI 把自己的语音识别项目 Whisper 开源了,声称能把视频和语音文件转换成文字。听说效果能和科大讯飞那些收费产品一较高下,而且最妙的是,这玩意儿不需要 GPU,家用电脑就能跑!
我是个折腾爱好者,尤其对这种开源项目兴趣满满。官方文档固然详细,但我这次打算走个捷径,找到了一个基于 Whisper 的 web 服务项目,直接用 Docker 部署,听起来是不是很酷?
下载 Docker 镜像
在 Docker 里搜索 openai-whisper-asr-webservice,拉下第一个镜像。
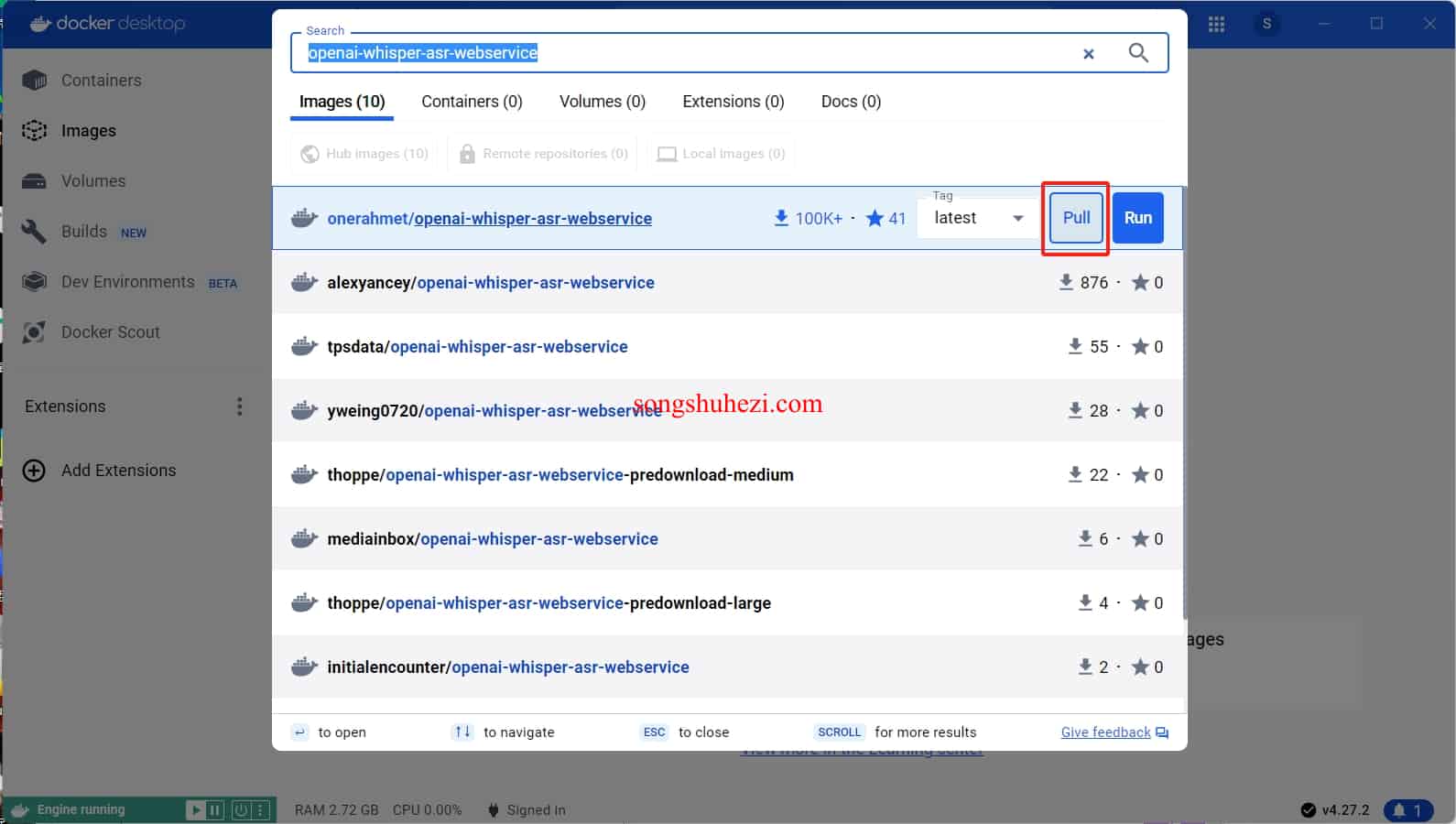
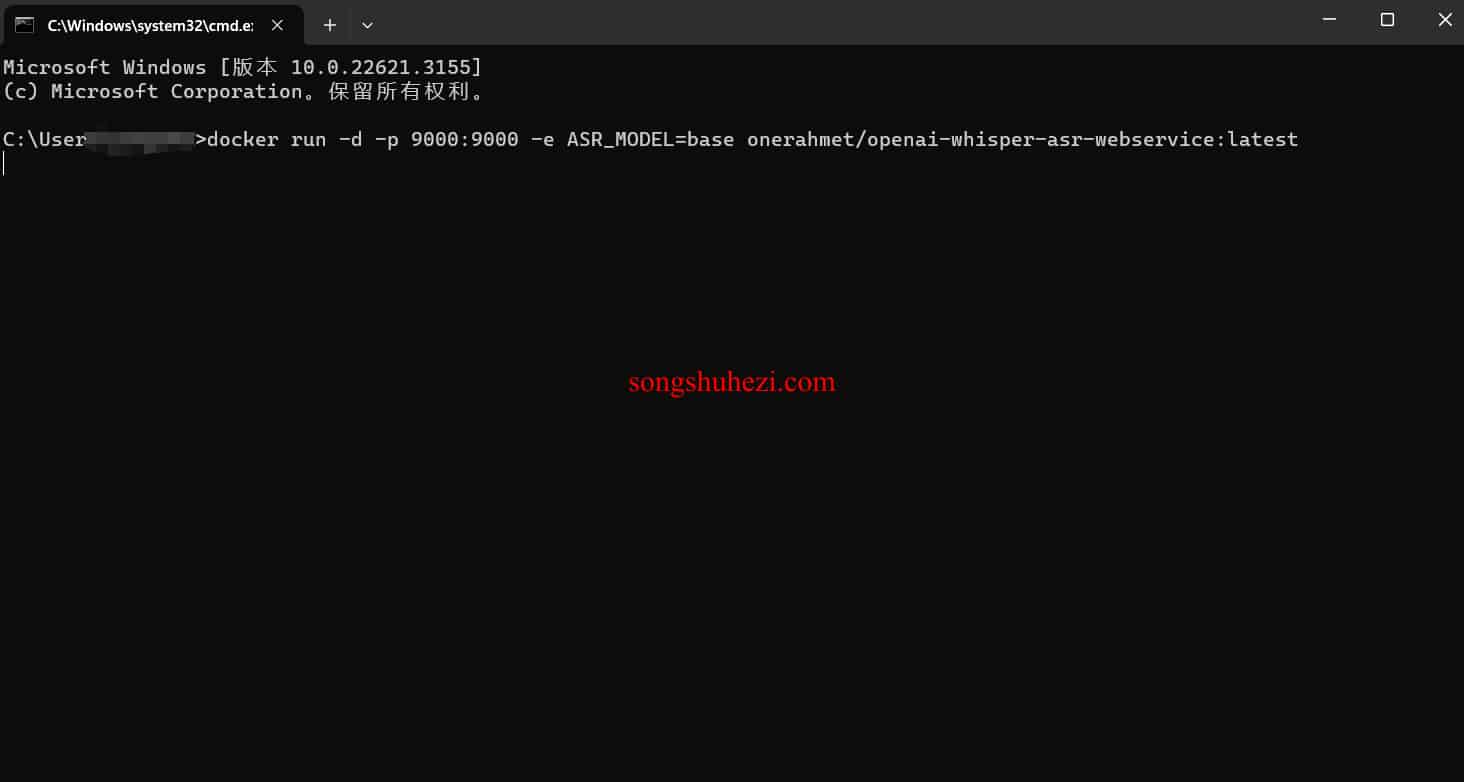
启动服务
docker run -d -p 9000:9000 -e ASR_MODEL=base onerahmet/openai-whisper-asr-webservice:latest
运行完毕后,打开浏览器访问 http://localhost:9000/,初次访问会下载模型,稍等片刻后,就能看到部署成功的页面,简单至极!
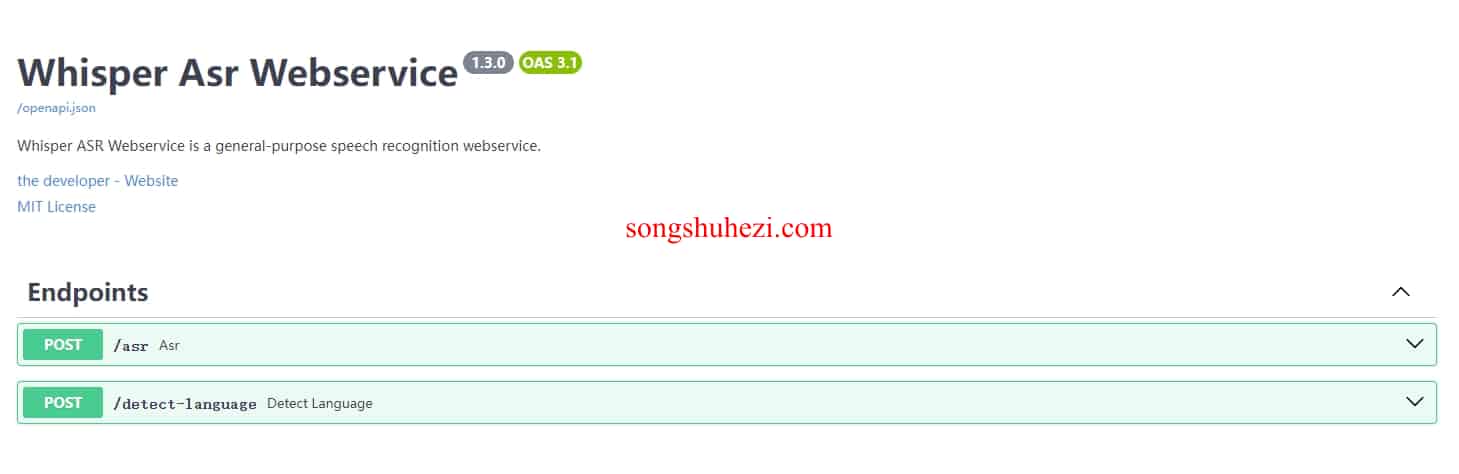
开始使用
提供了两个 HTTP 接口:语音识别和语言检测。语音识别接口,上传文件后转换成文字;语言检测接口,则是识别上传文件的语言类型。
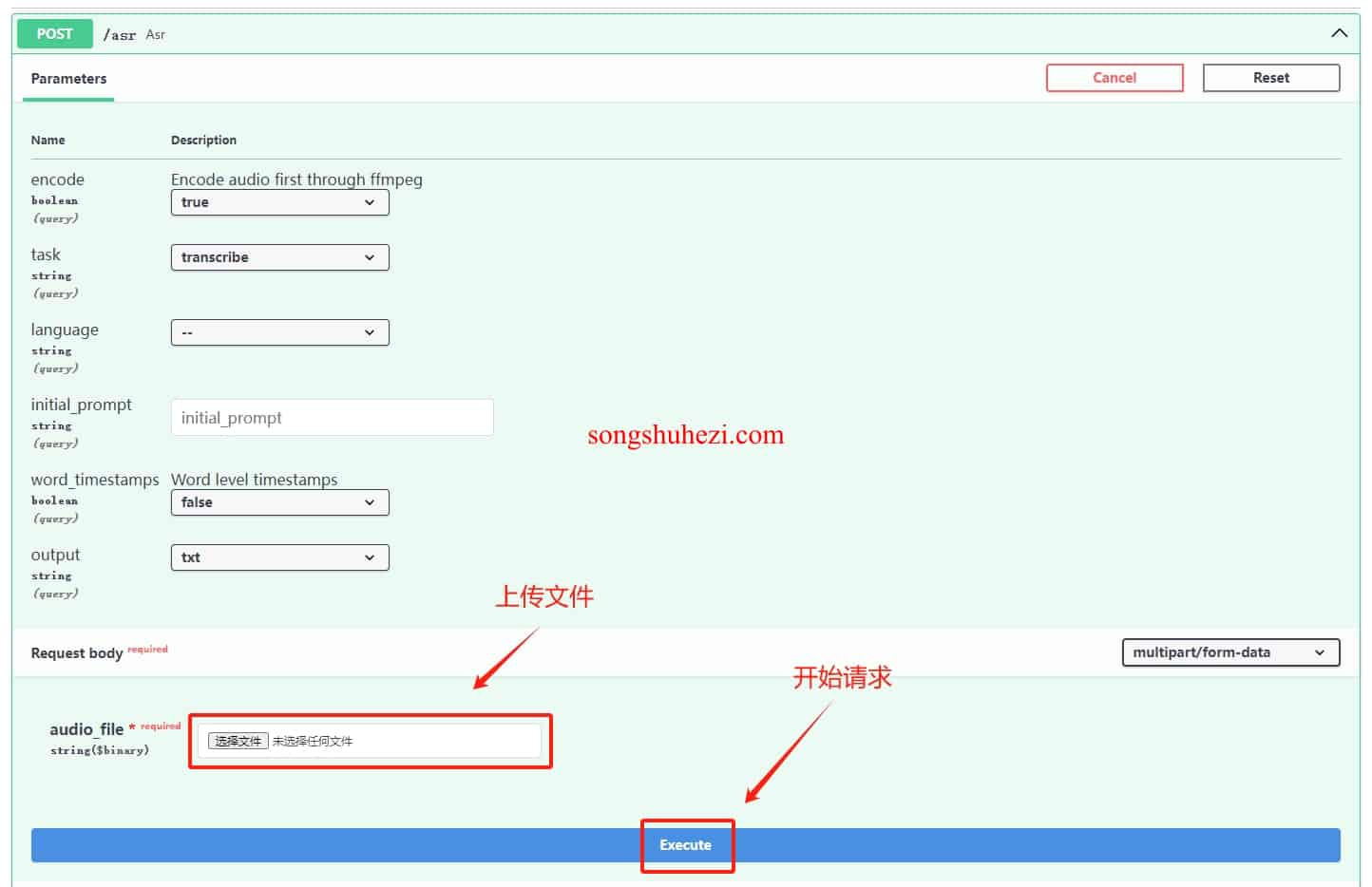
音/视频转文字
试了下英文音频,上传后点击执行,一会儿工夫就看到了转换结果。
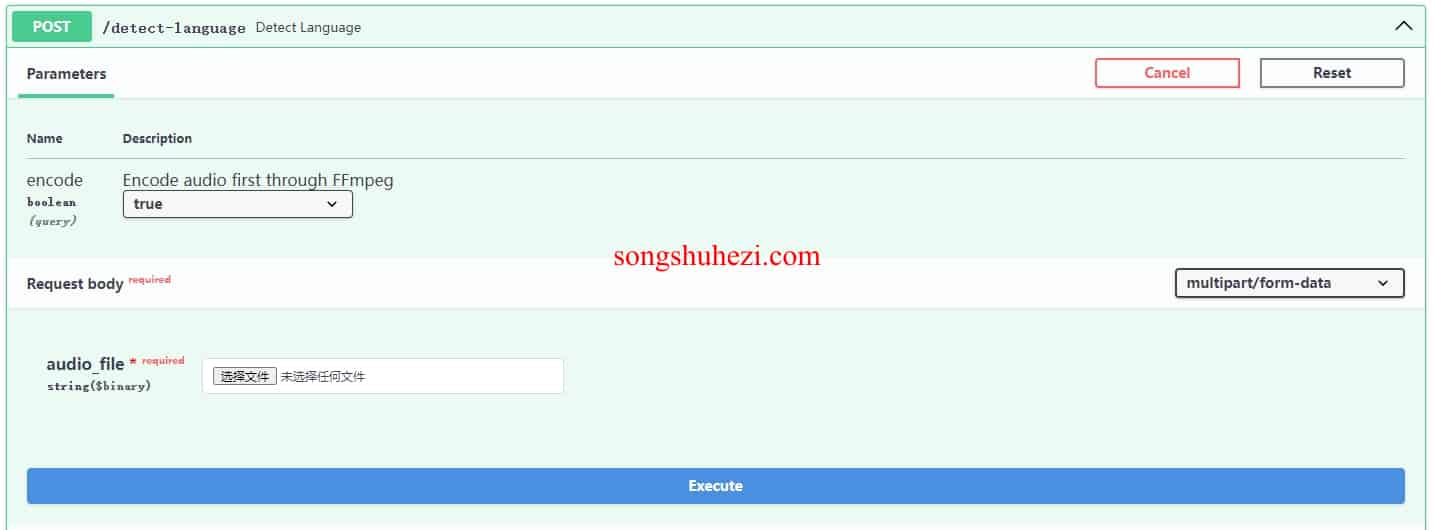
语言检测
还能检测视频或音频文件里的语言类型,这对于多语言文件也是非常友好的。
OpenAI的Whisper项目通过其开源和容易部署的特性,为广大用户和开发者提供了一个强大的语音识别工具。它不仅能够处理复杂的语音识别任务,还降低了技术门槛,使得更多的人能够利用这一技术。通过Docker容器化技术,Whisper的部署和使用变得前所未有的简单,进一步推动了人工智能技术的普及和应用。

反爬虫抓取,人机验证,请输入验证码查看内容
请扫描上方公众号二维码,发送关键字:2024,获取验证码。
微信搜索公众号:“程序员老鬼”或者“chatgpt1499” 或微信扫描右侧二维码关注微信公众号






反爬虫抓取,人机验证,请输入验证码查看内容
请关注本站公众号回复关键字:“2024”,获取验证码。
微信搜索公众号:“程序员老鬼”或者“chatgpt1499” 或微信扫描右侧二维码关注微信公众号


 RSS
RSS