






通过Monica使用Gemini 2.0模型聊天
说到 AI 技术,大家可能早已习惯了文字、语音助手的应用,但你有没有想过,AI 还能在图像、音频甚至多模态输出上做得更好?今天咱们就来聊聊 Monica 中的 Gemini 2.0,这款多模态 AI 可以说是为我们打开了一个全新的技术大门。无论是图像处理、音频分析,还是复杂任务规划,Gemini 2.0 都能轻松搞定。接下来,我就带大家一起看看它的具体功能和使用方法。
首先,咱们得明白,Gemini 2.0 是个什么东西。简单来说,它就是一个多模态 AI 系统,能处理多种输入,比如图像、音频、文本,还能通过这些输入生成各种输出,比如高质量的图片、精准的语音或是复杂的任务结果。它的核心亮点在于速度快、精度高,还能无缝整合各种工具。下面咱们一步步来拆解它的功能。
图像识别与洞察:不仅看得清,还看得懂
用 Gemini 2.0 处理图像,真的可以用“快、准、狠”来形容。它不仅能识别图片中的物体和场景,还能理解图片背后的情感和意义。比如,你上传一张风景照,它不仅能告诉你这是山还是海,还能分析出照片的整体氛围是宁静还是活泼。
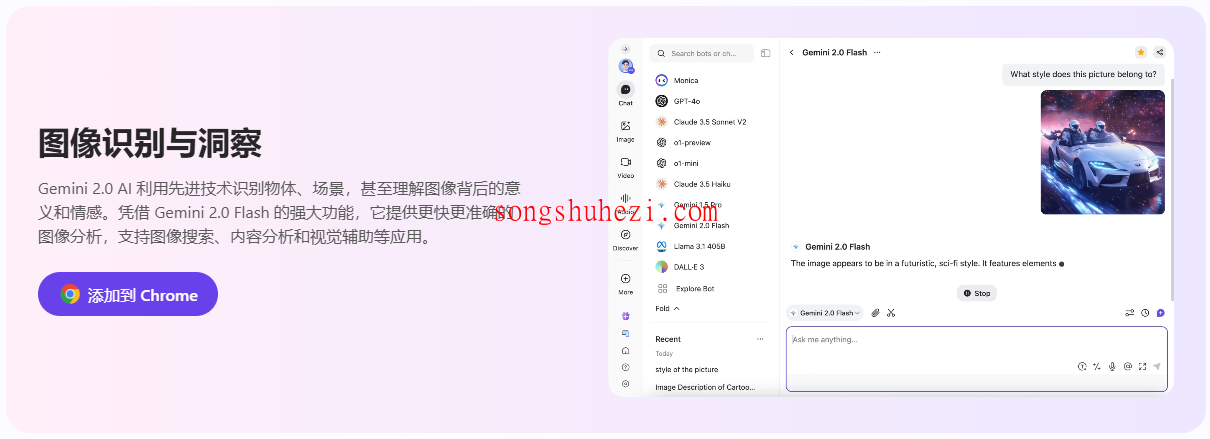
如果你需要用它来开展工作,比如做内容分析或者图像搜索,只需要上传图片,Gemini 2.0 就能迅速给出详细的分析结果。通过 Monica 的界面,你可以直接拖拽图片到输入框,然后选择“图像分析”功能,几秒钟后结果就出来了。对于需要视觉辅助的场景,比如帮助盲人用户描述图片内容,这个功能简直不要太贴心。
音频分析:听懂世界的每一个声音
除了看得懂,Gemini 2.0 还特别擅长“听”。它能精准识别语音、音乐甚至环境音效。比如你录一段嘈杂环境里的对话,它能迅速分离出人声并转化成文字,或者直接告诉你背景里有哪些声音——汽车鸣笛、鸟叫还是人群喧哗。

在 Monica 中使用音频分析也很方便。你只需要上传音频文件,或者直接用麦克风录音,然后选择音频分析功能。Gemini 2.0 会自动处理音频,并生成详细的分析报告。如果你是音乐创作者,还可以用它来分离乐器音轨,甚至生成和弦建议,简直是音乐人的好帮手。
多模态生成:图文语音,一次搞定
Gemini 2.0 的另一个杀手锏就是多模态生成。它能把图像、文本和语音结合起来,比如你输入一段文字,它不仅能生成对应的语音,还能配上一张相关的图片。这个功能特别适合做多语言内容创作,比如制作带有语音解说的短视频,或者生成多语言的宣传材料。
在 Monica 中操作也很简单。比如你想生成一段带语音的图文内容,只需要在输入框里输入文字,然后选择“多模态生成”。系统会根据你的需求自动生成对应的图片和语音,你还能进一步调整语音的语调和语言。
工具调用:效率提升的秘密武器
Gemini 2.0 还有一个特别实用的地方,就是它可以调用各种外部工具。比如你需要查询某个专业术语的定义,它会直接调用 Google 搜索;如果你需要执行一段代码,它还能帮你快速运行。更厉害的是,它支持多工具组合,能一次性完成复杂任务。
想象一下,你需要从一组图片中提取文字,再翻译成另一种语言,最后生成一份语音解说。以前可能需要用好几个软件,现在只需要 Gemini 2.0 一步搞定。你只要把图片上传到 Monica,选择“工具组合”功能,系统会自动完成所有步骤,效率提升不止一点点。
长上下文理解:记住你的偏好
每次用 AI 工具的时候,是不是都觉得它像个“健忘症患者”?每次都得重新输入你的需求?在这方面,Gemini 2.0 真的很贴心。它支持长上下文记忆,可以记住你最近 10 分钟的对话内容。比如你之前让它帮你分析了几张图片,接下来你再问它相关的问题,它还能接着上次的内容回答你。
要启用这个功能,只需要在 Monica 的设置里打开“上下文记忆”选项。之后,无论是图像分析还是任务规划,它都会记住你的偏好,提供更个性化的服务。
高性能与低延迟:速度与激情
最后不得不提的是它的性能。得益于 Gemini 2.0 Flash 技术,响应速度比之前快了一倍。尤其是在处理实时音视频流的时候,几乎感觉不到延迟。比如你用它来做实时字幕生成,或者处理直播中的观众提问,它都能迅速给出结果。
在 Monica 中使用这些功能时,界面也非常流畅。你可以直接上传实时流媒体,系统会自动识别并生成对应的分析结果。对于需要快速响应的场景,比如新闻直播或者在线教育,这个功能可以说是神器级别的存在。
最后
总的来说,Gemini 2.0 是一个功能强大又贴心的多模态 AI 工具。无论是图像、音频还是复杂任务,它都能轻松搞定,而且操作起来也很简单。尤其是结合 Monica 的界面,几乎没有学习成本。如果你对 AI 感兴趣,或者需要一个高效的工具来提升工作效率,真的可以试试看 Gemini 2.0。反正我用了之后,感觉自己的效率都翻倍了!

反爬虫抓取,人机验证,请输入验证码查看内容
请关注本站公众号回复关键字:“2024”,获取验证码。
打开微信扫描上方二维码关注微信公众号



 RSS
RSS