






如何导入文本数据至知识库
大家平时用Dify的时候,有没有遇到过需要导入大量文本数据的情况?其实,Dify的知识库功能特别强大,不仅支持本地文件上传,还能直接导入Notion数据,甚至可以抓取网页内容!下面我就来手把手教你怎么操作,保证你看完就能上手。
上传本地文件
首先,咱们先说最简单的方式——上传本地文件。你可以在Dify平台顶部导航中找到“知识库”,然后点击“创建知识库”。接着,直接拖拽或者选择文件上传即可。支持批量上传哦,不过这里有些小限制:
- 单个文件大小不能超过15MB。
- 批量上传的数量和总上传量取决于你的订阅计划。
- 向量存储空间也是有限的,具体看你的SaaS版本。
所以,如果你有大量文件要上传,记得先确认你的订阅计划是否够用。
导入在线数据
要是你觉得本地文件上传还不够酷,那Dify还支持在线数据导入!目前支持两种在线数据来源:Notion和网页抓取。
从Notion导入数据
如果你是Notion的重度用户,这个功能绝对会让你眼前一亮。Dify不仅支持从Notion导入数据,还能实现后续的自动同步。操作步骤如下:
1.授权验证
在创建知识库时,选择数据源为“同步自Notion内容”,然后点击“去绑定”。按照提示完成授权验证。或者,你也可以进入“设置” -> “数据来源” -> “添加数据源”,绑定Notion。

2.导入Notion数据
完成授权后,回到创建知识库页面,选择需要的Notion页面进行导入。
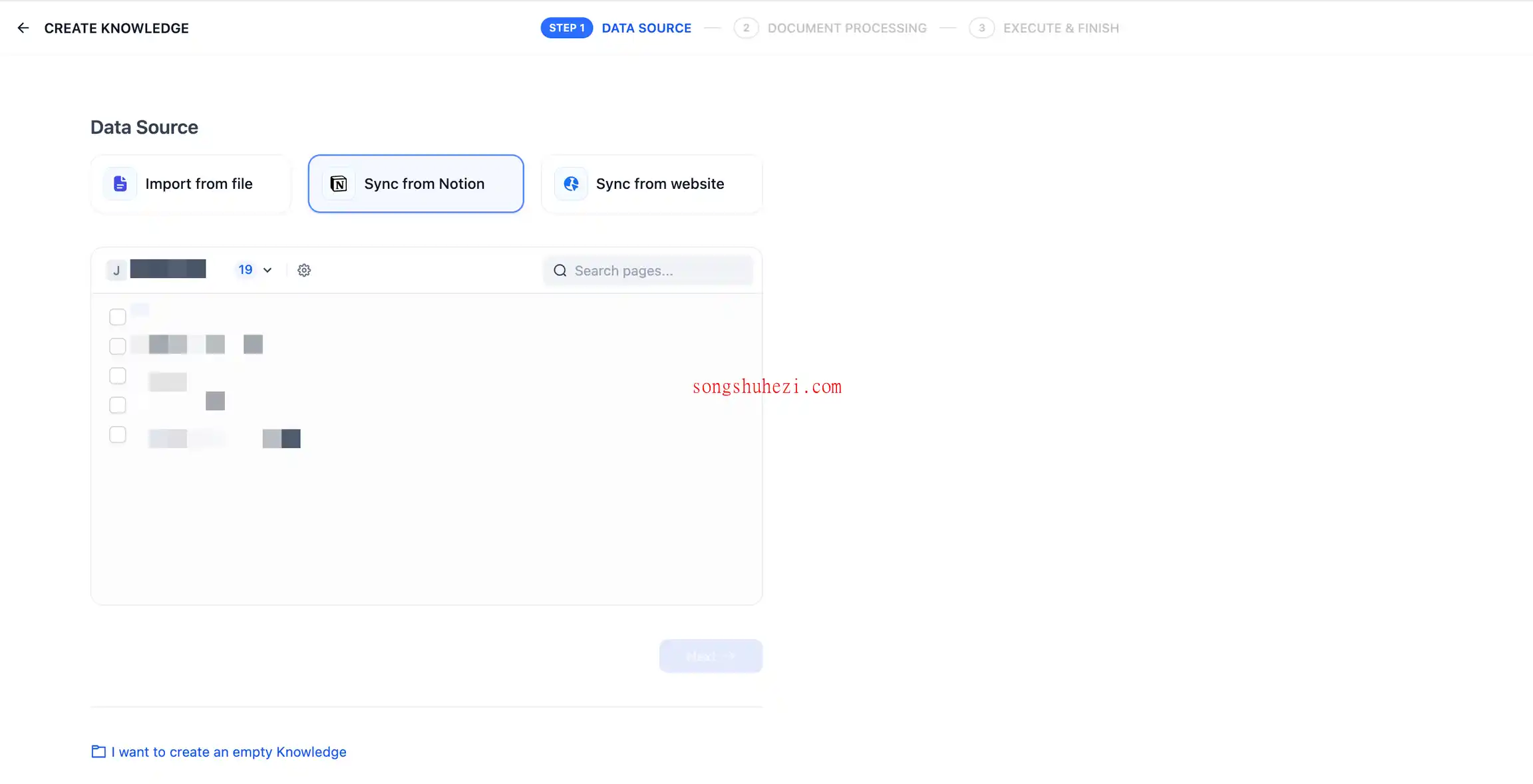
3.分段与清洗
选择分段设置和索引方式,保存后Dify会自动处理数据。Dify不仅支持普通页面,还能处理database类型的页面属性。不过目前还不支持导入图片和文件,表格类数据会被转换为文本展示。
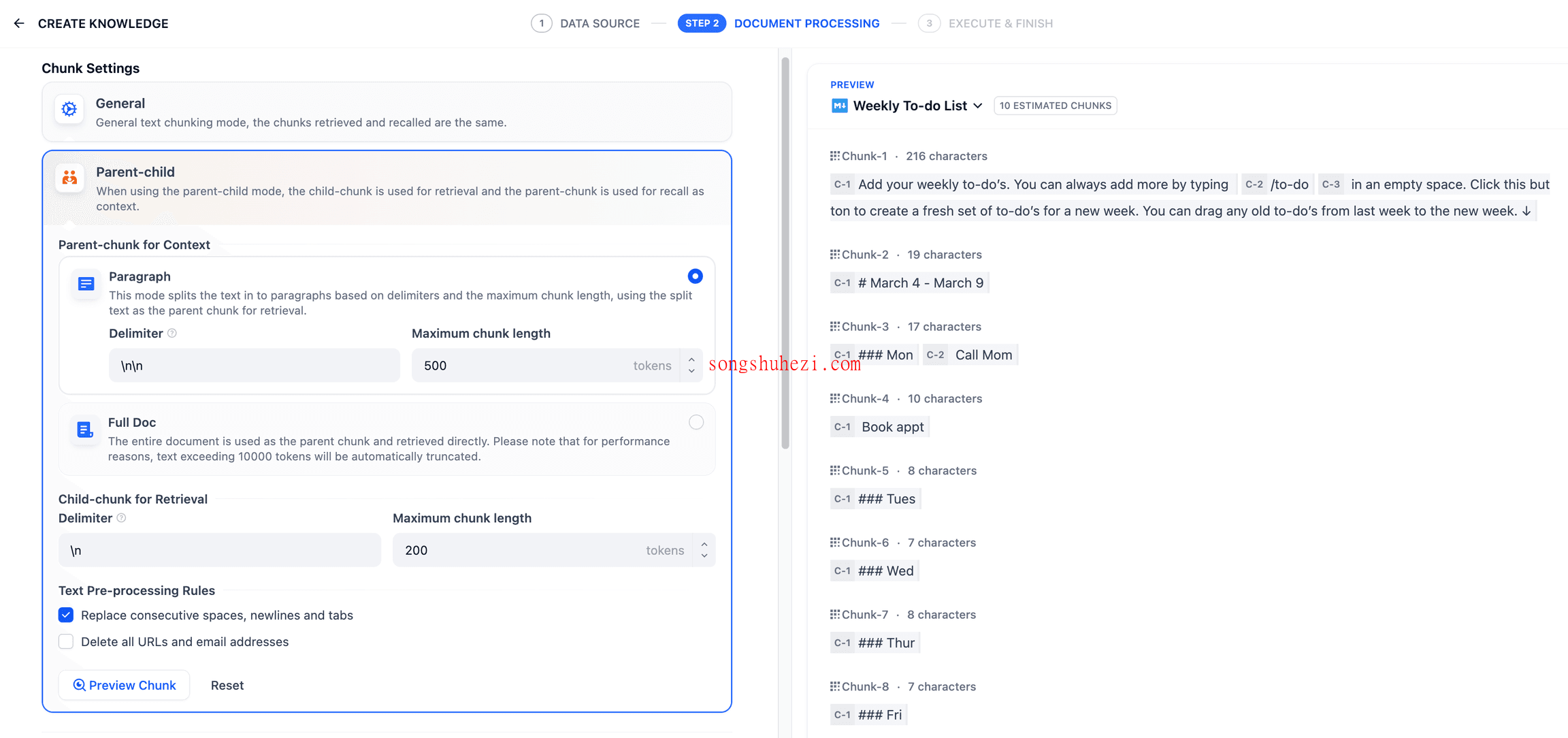
4.同步Notion数据
如果Notion内容有更新,可以在知识库的文档列表页中点击“同步”按钮进行更新。不过,记得同步过程会消耗嵌入模型的Tokens哦。
Notion集成配置
Notion的集成方式分为两种:internal集成和public集成。
- internal集成:适合工作区所有者,创建集成后复制Secrets并配置到Dify的
.env文件中。 - public集成:需要将internal集成升级为public集成,填写公司信息后获取Client ID和Client Secret,同样配置到
.env文件中。
配置完成后,你就可以愉快地导入和同步Notion数据啦!
从网页导入数据
如果你需要从网页抓取内容,Dify也提供了两款开源工具:Firecrawl和Jina Reader。这两款工具可以将网页内容解析为Markdown格式,非常适合用来喂给大语言模型。
使用Firecrawl抓取网页内容
1.配置Firecrawl凭据
登录Firecrawl官网注册账号,获取API Key后填入Dify的数据源配置页面。

2.抓取网页内容
在知识库创建页选择“Sync from website”,provider选Firecrawl,填入目标URL。你可以设置抓取子页面、抓取深度等参数,然后点击“Run”开始抓取。
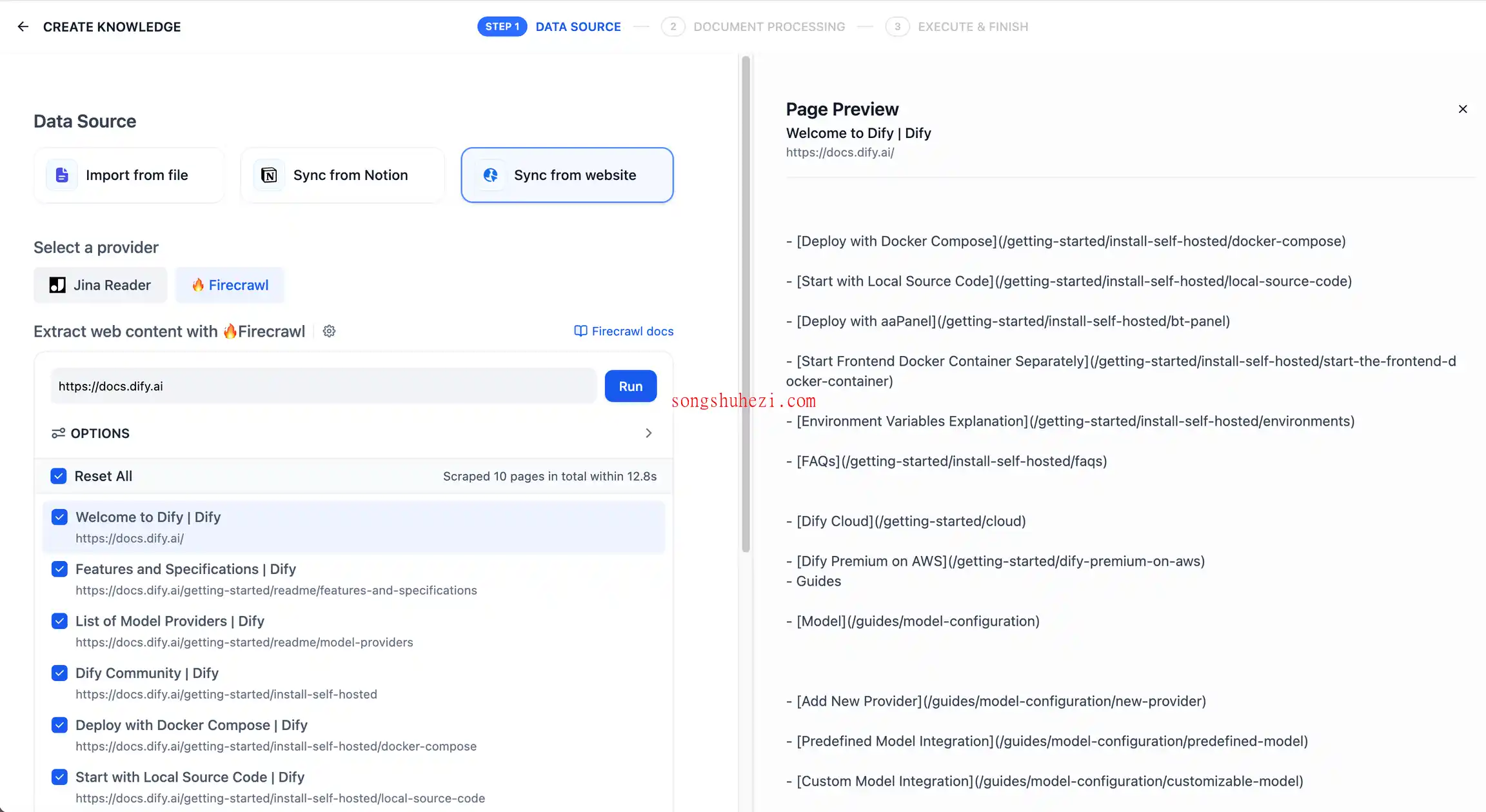
3.查看抓取结果
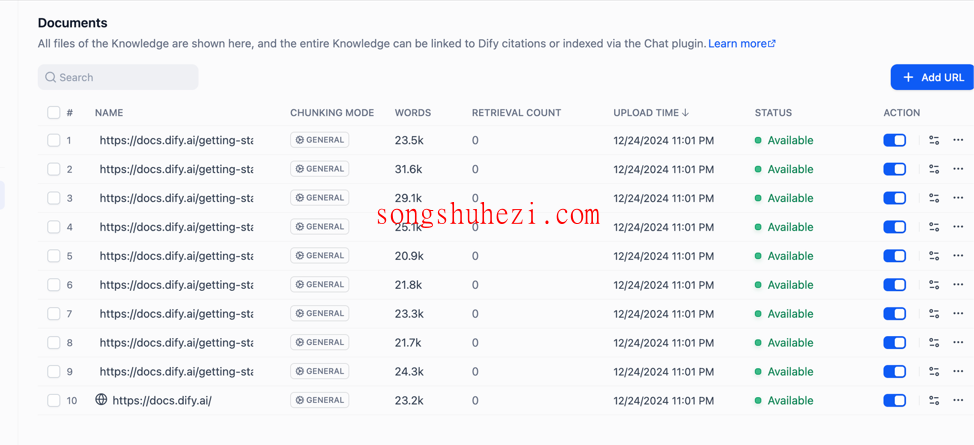
抓取完成后,网页内容会被存储到知识库中。如果需要继续抓取新网页,可以点击“Add URL”添加新地址。
使用Jina Reader抓取网页内容
- 配置Jina Reader凭据
登录Jina Reader官网注册账号,获取API Key后填入Dify的数据源配置页面。 - 抓取网页内容
在知识库创建页选择“Sync from website”,provider选Jina Reader,填写目标URL。设置抓取参数后点击“Run”开始抓取。 - 查看抓取结果
抓取完成后,网页内容会被存储到知识库中。需要添加新网页时,点击“Add URL”继续导入。
注意事项
需要特别提醒的是,如果你的知识库已经引用了在线数据来源,就不能再新增本地文档了,也不能变更为本地文件类型的知识库。这是为了避免数据来源混杂导致管理困难。
我的感觉是,这些功能真的特别贴心,尤其是Notion同步和网页抓取,简直是效率神器!不管你是搞知识管理还是数据整理,用Dify都能让你事半功倍。如果你还没试过,赶紧去试试吧,绝对不亏!

反爬虫抓取,人机验证,请输入验证码查看内容
请关注本站公众号回复关键字:“2024”,获取验证码。
打开微信扫描上方二维码关注微信公众号



 RSS
RSS