






设定索引方法与检索设置:高效管理知识库
选定内容的分段模式后,接下来设定对于结构化内容的索引方法与检索设置。
在构建知识库时,索引方式和检索设置直接决定了检索效率和回答的准确性。就像搜索引擎依赖高效的算法来快速找到网页内容一样,合理的索引方法和检索设置能帮助语言模型(LLM)更精准地获取信息。本文将带你详细了解如何设定索引方法,以及高质量和经济两种模式的特点与应用场景。
设定索引方法
在选择索引方法时,你可以根据需求选择“高质量”或“经济”两种模式。每种模式都有其独特的适用场景和检索设置选项。
高质量模式
高质量模式通过 Embedding 嵌入模型,将分段后的文本块转换为数字向量,帮助压缩和存储大量文本信息。这种方式使得用户的问题与文本之间的匹配更加精准。
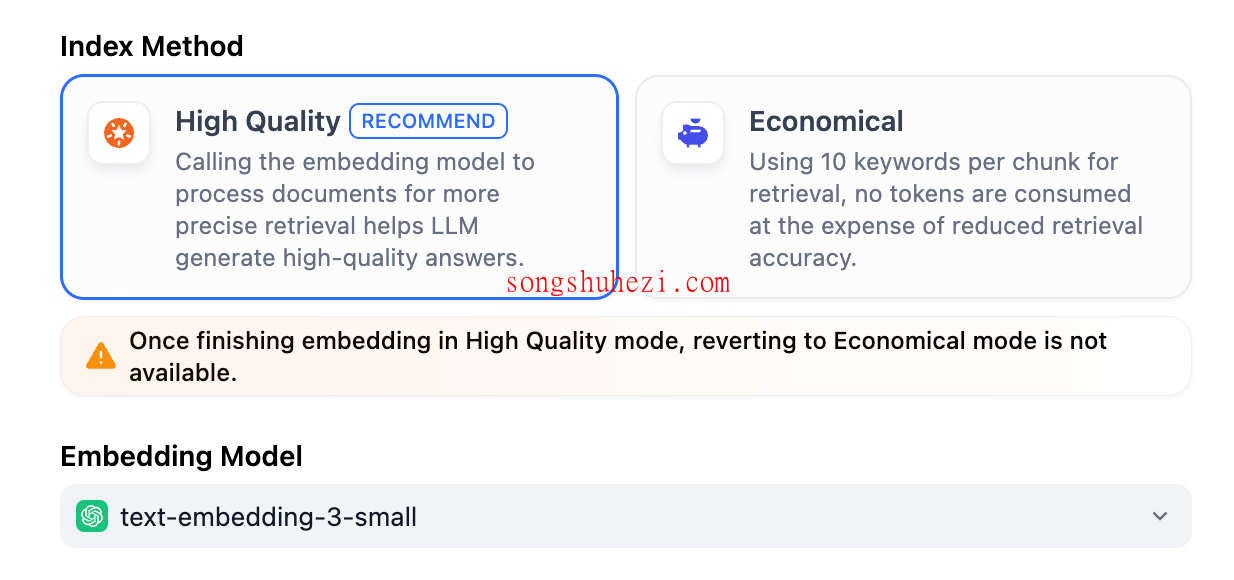
高质量模式支持以下三种检索设置:
- 向量检索
- 全文检索
- 混合检索
需要注意的是,一旦选择高质量模式,知识库的索引方式无法降级为经济模式。如果需要切换,建议重新创建知识库。
此外,高质量模式下还可以启用 Q&A 模式(仅适用于社区版)。这种模式会对文本进行分段并生成 Q&A 匹配对,采用“Q to Q”(问题匹配问题)策略,而不是常见的“Q to P”(问题匹配段落)策略,支持中、英、日三种语言。
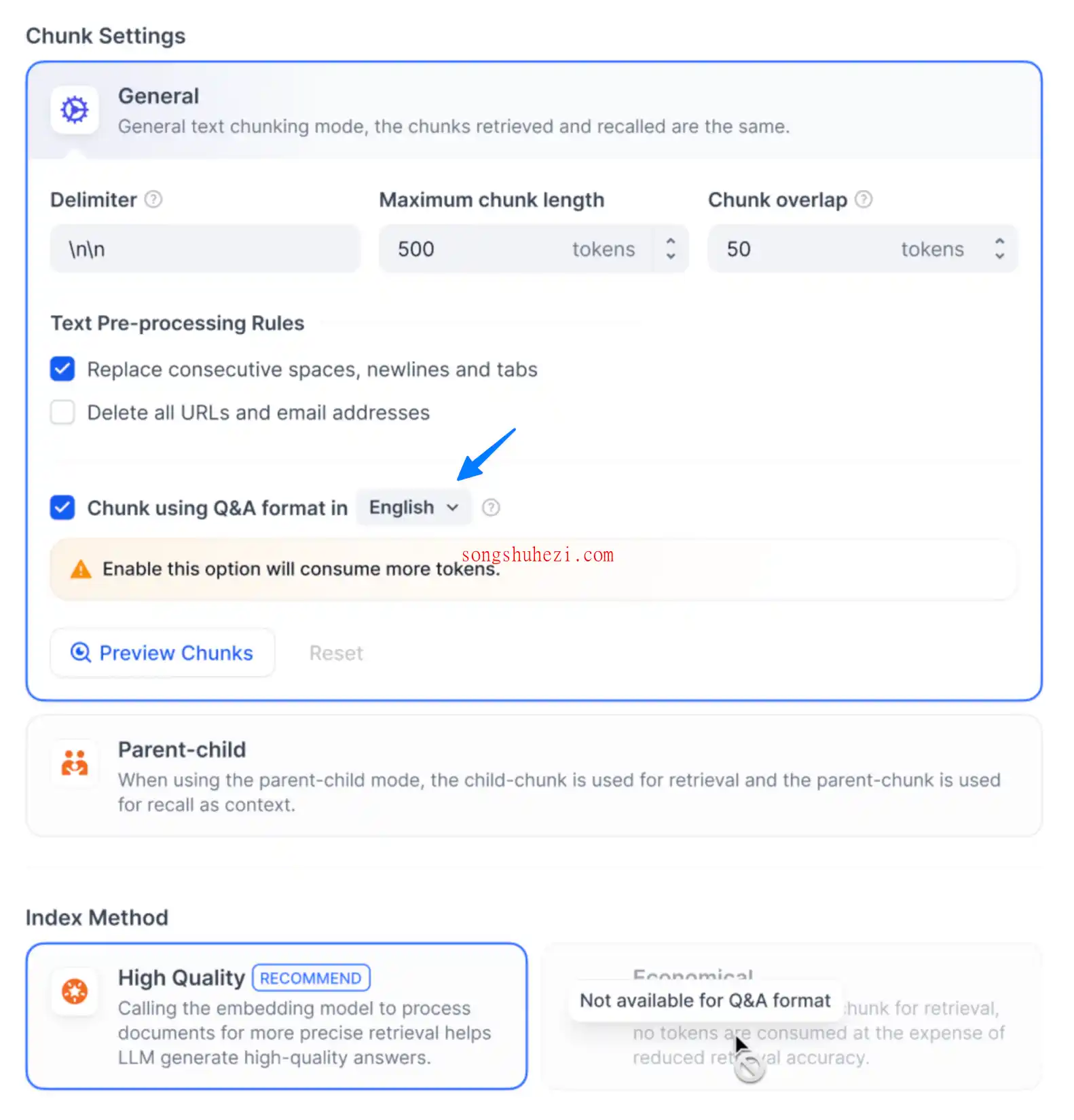
经济模式
相比高质量模式,经济模式更加注重资源的节约,适用于计算资源有限的场景。不过,经济模式的检索设置相对简单,不支持向量检索等高级功能。
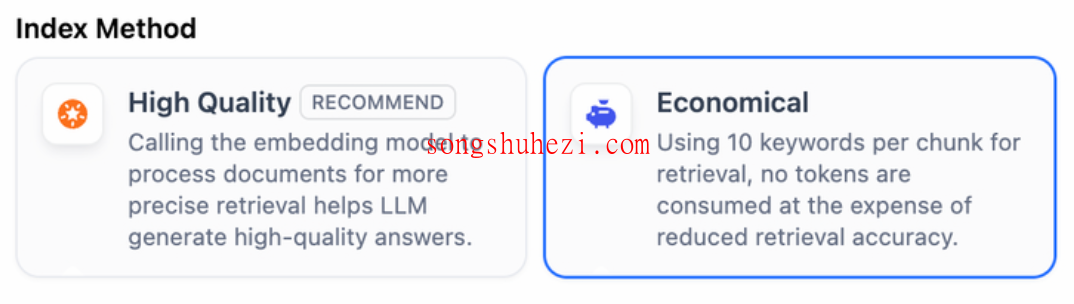
指定检索方式
知识库的检索方式决定了 LLM 能获取的背景信息,从而影响回答的准确性和可信度。以下是高质量索引方式下的三种检索设置:
1. 向量检索
向量检索通过将用户问题和文本块转化为向量,计算它们之间的相似度来匹配内容。
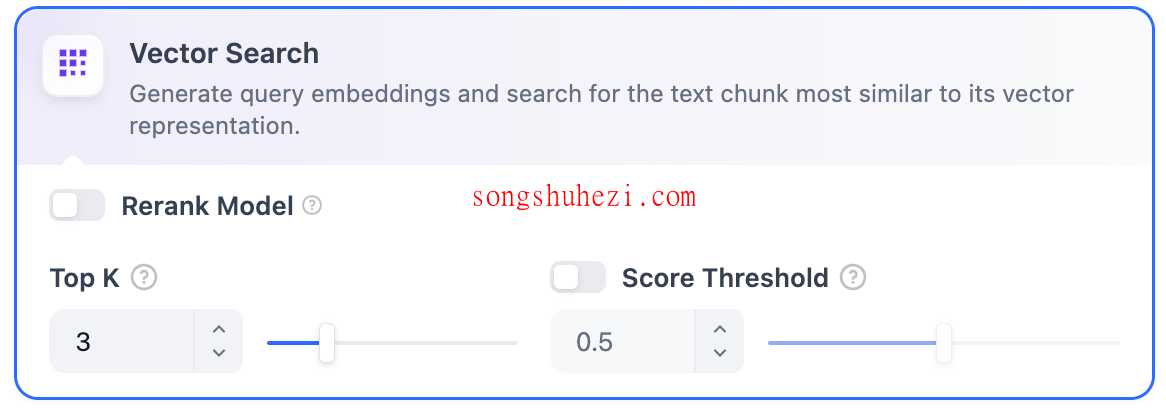
主要设置包括:
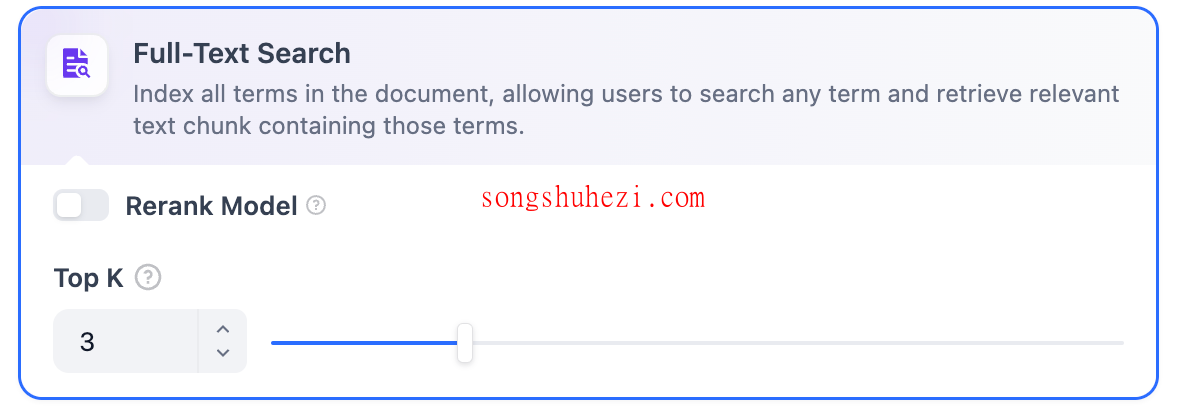
- Rerank 模型:默认关闭。开启后,可以使用第三方模型对召回的内容重新排序,优化输出质量。
- TopK:设置筛选与用户问题相似度最高的文本片段数量,默认值为 3。
- Score 阈值:设置相似度的最低分数,默认值为 0.5。
Rerank 模型需提前配置 API 秘钥,开启后会消耗额外的 Tokens。
2. 全文检索
全文检索基于关键词匹配,通过倒排索引快速找到相关文本片段。设置选项与向量检索类似,包括 Rerank 模型、TopK 和 Score 阈值。
3. 混合检索
混合检索结合了向量检索和全文检索的优点
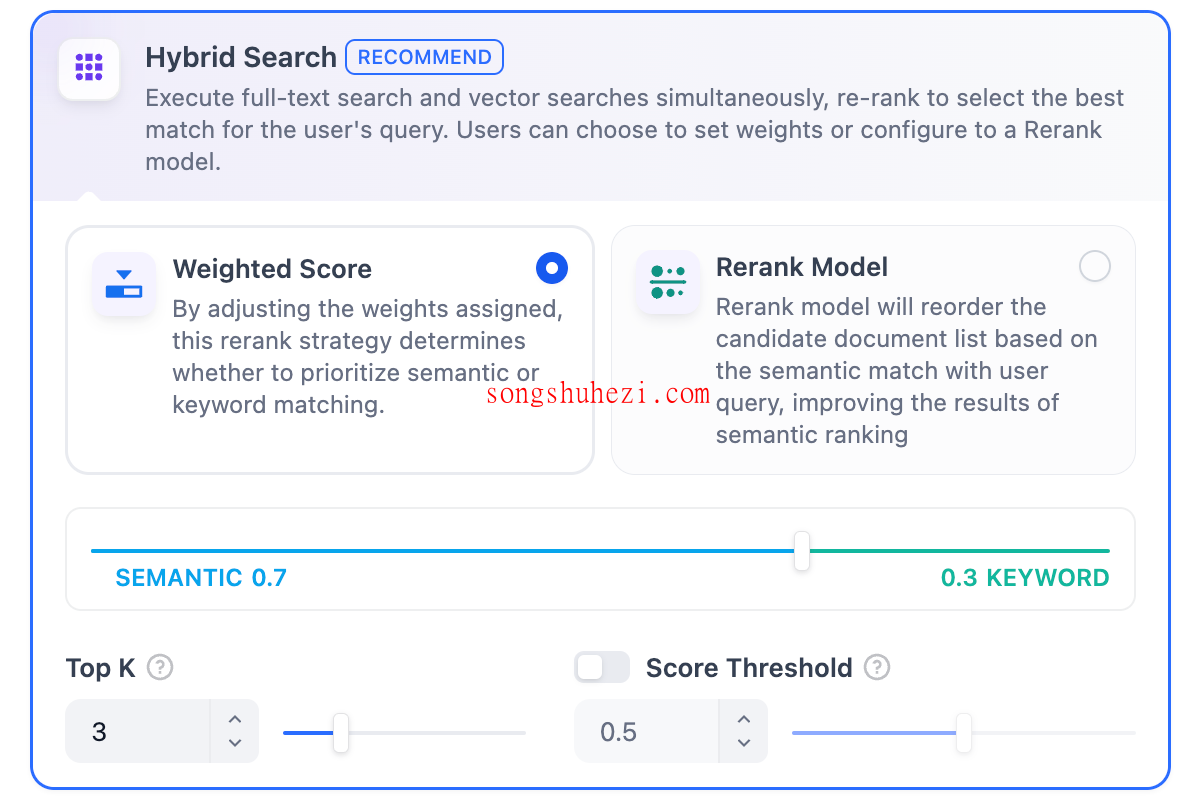
可以通过以下方式优化结果:
- 权重设置:调整语义检索与关键词检索的权重比例,灵活应对不同业务场景。
- Rerank 模型:对召回的内容进行重排序,提升匹配精度。
检索设置的灵活性
在高质量索引设置下,你可以根据实际需求调整以下参数:
- TopK:决定召回的文本片段数量。数值越高,召回的片段越多。
- Score 阈值:限制召回片段的相似度分数,提高结果的精准性。
此外,混合检索还支持自定义语义和关键词的权重比例。例如:
- 将语义权重调至 1:仅启用语义检索,适合处理多语言内容。
- 将关键词权重调至 1:仅启用关键词检索,适合明确查询场景。
高质量索引与 Q&A 模式
如果你的知识库内容以常见问题文档为主,可以考虑启用 Q&A 模式。这种模式直接匹配问题与答案,适用于高频和高相似度问题的场景。需要注意的是,Q&A 模式可能会消耗更多的 LLM Tokens。
设定索引方法和检索设置是知识库构建的核心环节。高质量模式虽然资源消耗较高,但能提供更精准的匹配结果;而经济模式则适合对性能要求不高的场景。至于检索设置,灵活调整 TopK、Score 和权重比例,可以根据实际需求优化检索效果。无论选择哪种方式,关键是找到最适合自己业务场景的组合,这样才能最大化地发挥知识库的价值。

反爬虫抓取,人机验证,请输入验证码查看内容
请关注本站公众号回复关键字:“2024”,获取验证码。
打开微信扫描上方二维码关注微信公众号



 RSS
RSS