






EasySpider树形结构的数据如何采集?
在网页数据采集中,有时我们需要采集树形结构的数据,并在Excel中清晰地展示出每一级的数据层次关系。比如,某些网页上的目录结构、文件系统或分类信息,都需要以层级的方式展示。在这种情况下,如何进行有效的采集呢?
问题背景
用户在采集网页数据时,页面内容具有明显的树形结构,需要在采集数据时保持这种层次关系,并在最终的Excel文件中清晰呈现。项目维护者提供了一种基于循环嵌套和动态XPath修改的方法,能够有效解决这一问题。

解决方案
以下是实现树形结构数据采集的具体步骤和方法:
嵌套循环设置:
树形结构的数据通常由父级到子级一层一层展开。为了获取每个层次的数据,可以通过多个循环嵌套的方式进行。你需要为每一级数据定义一个循环。动态修改XPath:
每个层级的XPath可能会根据父级和子级的数据动态变化。通过自定义变量,您可以在每个循环中动态设置XPath。示例:- 爷爷元素的循环XPath设置为:
/div[eval("self.a")] - 父元素的循环XPath设置为:
/div[eval("self.a")]/div/div[eval("self.b")] - 子元素的XPath设置为:
/div[eval("self.a")]/div/div[eval("self.b")]/div
其中,
self.a和self.b是自定义的变量,分别控制爷爷元素和父元素的循环。每个循环中可以动态调整XPath,使其对应不同的层次。- 爷爷元素的循环XPath设置为:
点击操作展开层级:
在每个循环内,首先设置一个点击操作,将当前层级的子级展开。这样可以保证你能够访问并采集到子元素的数据。数据提取与字段合并:
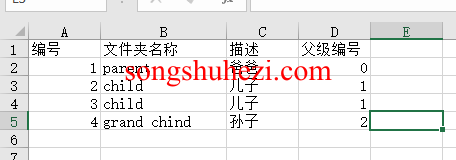
在每一级循环内,设置数据提取操作,确保提取的数据按相同的字段名称输出到Excel的同一行。例如:- 爷爷元素的字段名称设置为“文件夹描述”
- 父元素的字段名称也设置为“文件夹描述”
这样可以将不同层次的数据合并到同一行,保持数据的层级一致性。
父级编号的处理:
为了清晰展示层级关系,你还可以为每个层级的数据设置一个父级编号字段。通过JavaScript代码返回值,可以动态生成父级编号,例如:javascriptreturn "1"; // 假设这是第一级的编号这样可以确保每一级的数据都带有正确的层次编号,方便在Excel中进行区分和展示。
采集树形结构的数据需要通过循环嵌套来处理不同的层级,并且通过动态修改XPath来确保能够正确地提取每一层的数据。通过自定义变量和点击操作展开子级,可以有效获取所有层级的数据,并将其以清晰的层次关系展示在Excel表格中。如果你遇到类似的问题,可以按照上述步骤进行设置。


反爬虫抓取,人机验证,请输入验证码查看内容
请关注本站公众号回复关键字:“2024”,获取验证码。
微信搜索公众号:“RPA编程教程”或者“rpa1499” 或微信扫描上方二维码关注微信公众号



 RSS
RSS