






EasySpider对于rss地址,如xml文件地址该怎么处理
在使用EasySpider进行网络爬虫时,RSS地址(通常是XML格式的文件)经常会出现,尤其是在需要获取新闻源、博客更新等内容时。与常规网页不同,XML文件不支持可视化选择元素,因此我们需要通过XPath来提取其中的数据。今天我们就来看看如何使用EasySpider从RSS地址或XML文件中提取数据。
1. 场景描述
例如,你希望从这个RSS地址中提取新闻内容:
https://www.chinanews.com.cn/rss/scroll-news.xml
由于XML文件结构不同于HTML网页,无法直接通过可视化的方式选中元素,所以我们需要用XPath来定位和提取数据。
2. 解决方案
EasySpider虽然不支持直接可视化处理XML文件,但可以通过XPath来精确定位并提取我们所需的内容。以下是具体操作步骤:
第一步:打开开发者工具定位元素
首先,按下键盘上的F12键,打开浏览器的开发者工具。然后点击选择按钮(一般是一个像鼠标箭头的图标),选择想要提取的元素。比如在RSS文件中,我们通常需要提取的可能是新闻标题、链接或发布时间等。

第二步:复制XPath
定位到你想要的元素后,右键点击该元素,并选择“复制XPath”。这个XPath路径将帮助EasySpider找到你需要的元素。
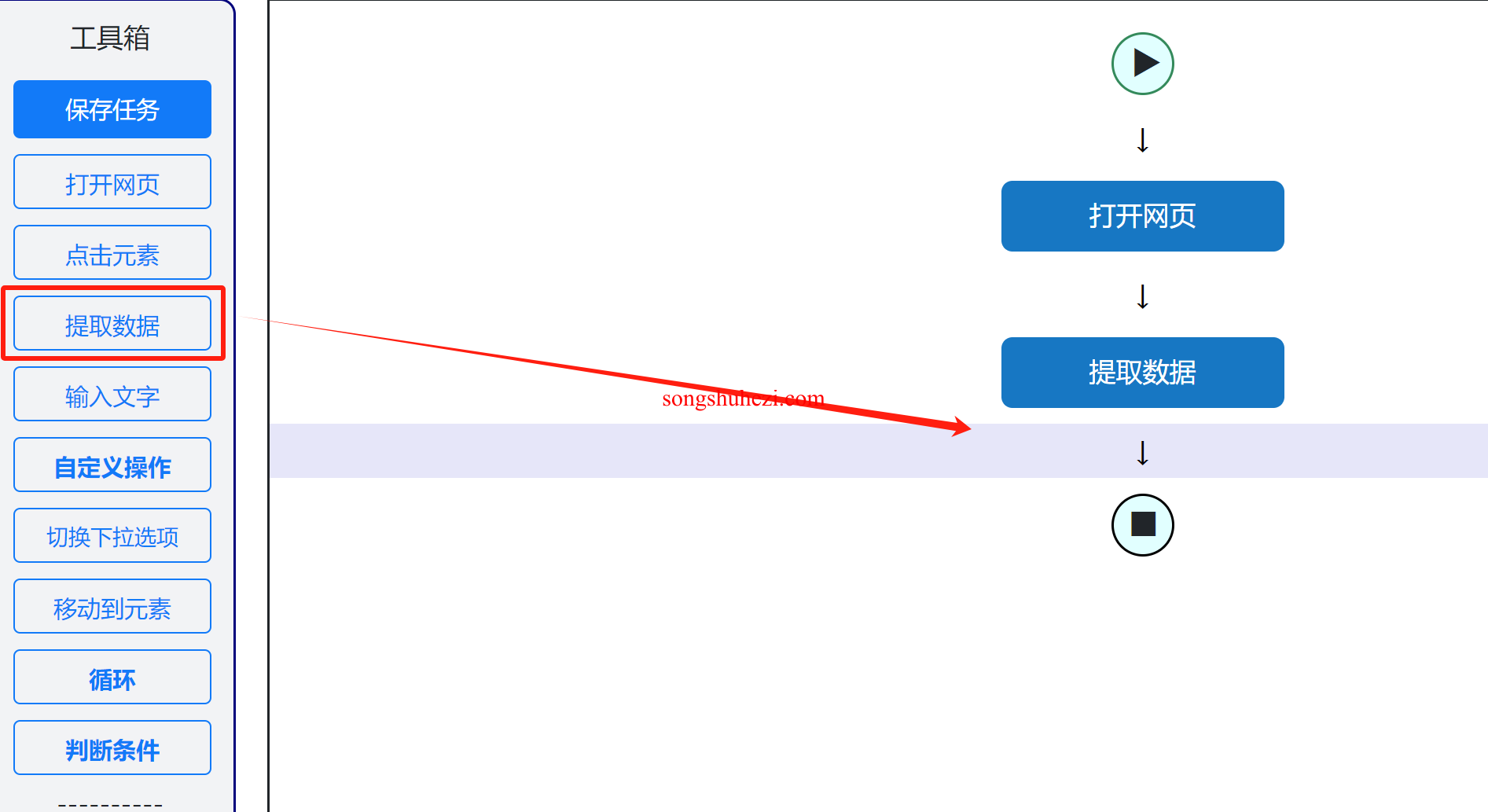
第三步:添加提取数据操作
回到EasySpider,在流程图界面左边找到“提取数据”操作,并将其拖动到流程图中合适的位置。这个步骤允许你将提取的XPath与实际字段关联起来。
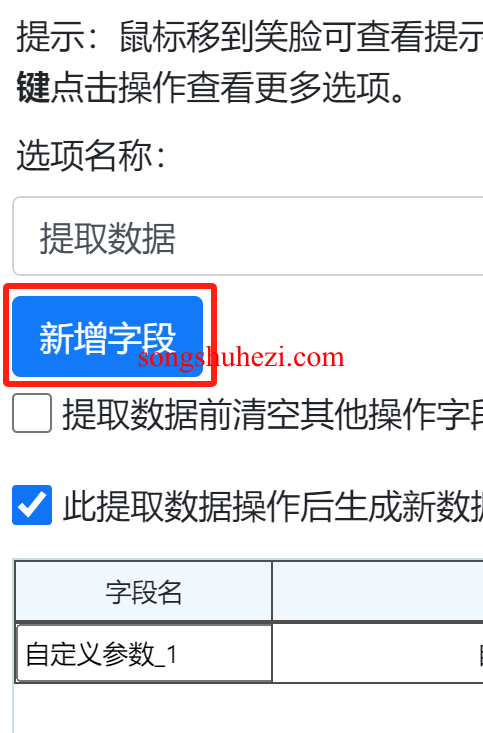
第四步:填写XPath并添加字段
在提取数据操作中,添加一个字段,例如“标题”或“链接”,并在XPath输入框中粘贴刚刚复制的XPath路径。这将确保你可以成功提取该元素的信息。
3. 如何处理循环提取
如果你需要从XML文件中提取多个元素,比如多个新闻条目,可以通过循环来实现:
添加循环:在流程图中添加一个“循环”操作,选择循环类型为“不固定元素列表”,并填入相应的XPath。该XPath通常指向多个相同类型的元素,如新闻条目。
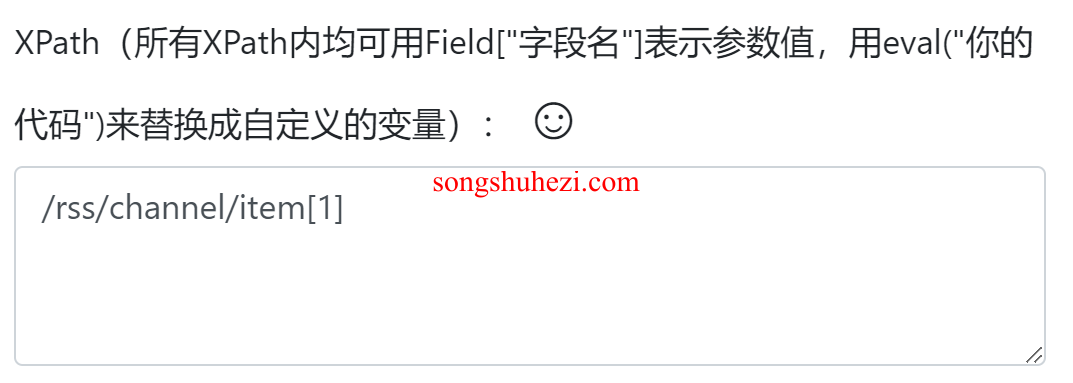
循环中提取数据:在循环中添加提取数据操作。填写相对循环的XPath,并勾选“使用相对循环内的XPath”选项。
JavaScript脚本:展开“自定义操作”按钮,在提取元素数据前,可以在JavaScript脚本处填写
1以确保顺利提取所有数据。
4. 代码示例
假设你要从RSS中提取每条新闻的标题和链接,相关的XPath可能如下:
- 新闻标题的XPath:
xpath
//item/title
- 新闻链接的XPath:
xpath
//item/link
你可以在EasySpider中添加这些字段,并使用对应的XPath来提取数据。
5. 适用场景
这种方法适用于各种XML文件的处理,特别是RSS源、API返回的XML格式数据等。通过灵活使用XPath,你可以从不同结构的XML文件中提取所需的内容,极大提升爬虫的效率和灵活性。
处理RSS地址中的XML文件数据可能看起来有些复杂,但通过XPath和EasySpider的结合,你可以非常轻松地从这些文件中提取所需的数据。只需按照步骤设置循环和提取操作,即可轻松抓取大量内容。
我的感觉是,使用XPath提取数据虽然不如可视化选择那么直观,但它提供了极大的灵活性,尤其在处理结构化的数据时特别有效。如果你需要从RSS源或其他XML文件中获取信息,不妨试试看!


反爬虫抓取,人机验证,请输入验证码查看内容
请关注本站公众号回复关键字:“2024”,获取验证码。
微信搜索公众号:“RPA编程教程”或者“rpa1499” 或微信扫描上方二维码关注微信公众号



 RSS
RSS