






EasySpider教程
EasySpider循环次数设定(包括无限循环)及检测到页面内容才提取数据
在进行自动化数据抓取时,遇到页面加载不完全的情况是常见的需求。如果页面加载不完全导致内容未显示全,自动化任务需要重复刷新页面,直到指定元素加载完成。本文将介绍如何在EasySpider中实现这一功能,并设置最多重试次数为15次。
任务设计思路
1. 固定次数的循环设置
在任务设计中,如果需要设定一个固定的循环次数(如最多重试15次),可以通过设置一个循环操作来实现。具体步骤如下:
拖动循环操作:在任务流程图的左侧,拖动一个循环操作到流程图中。
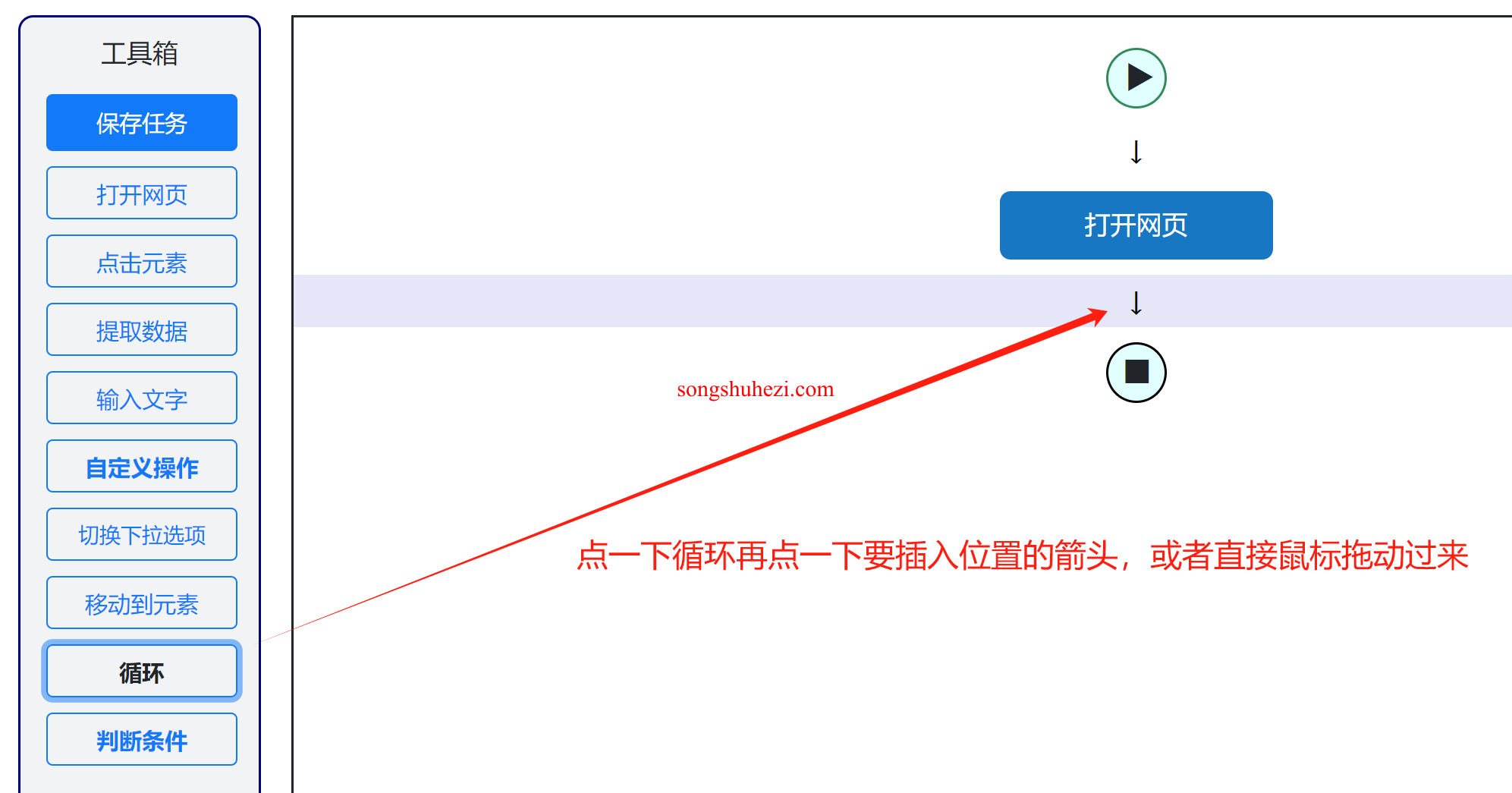
设置循环类型:
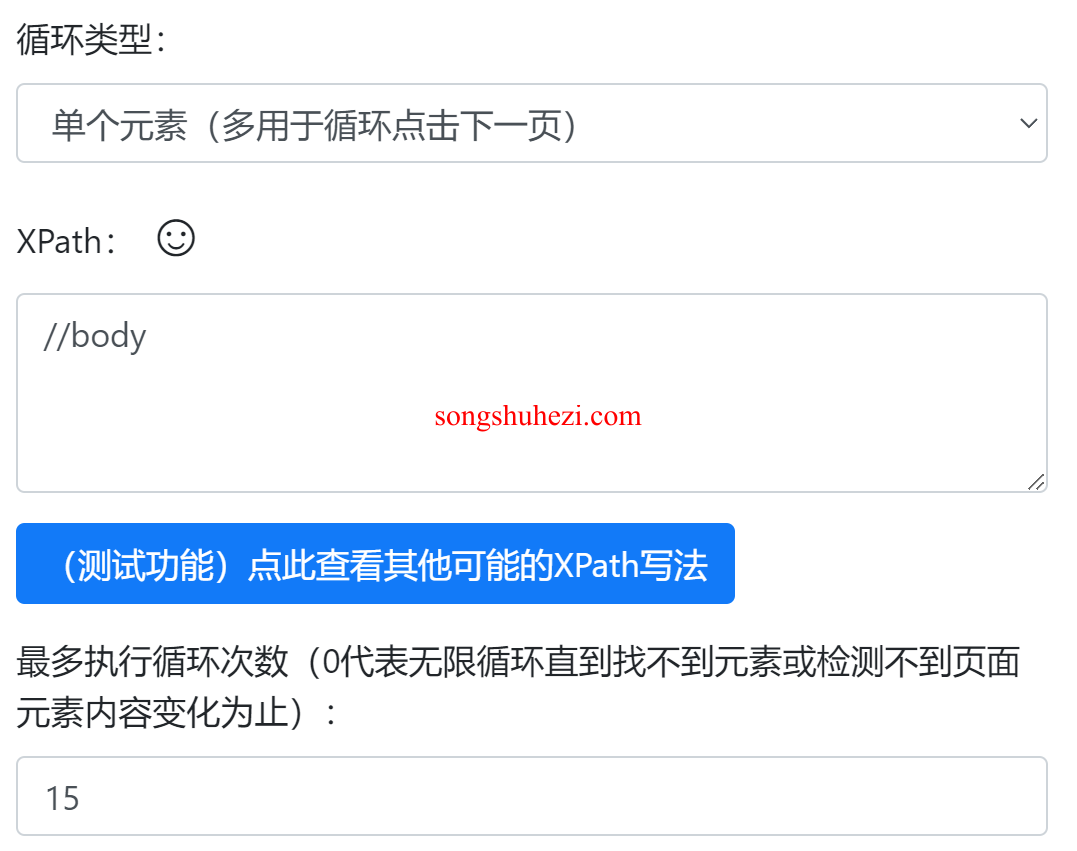
- 将循环类型设置为单个元素。
- 设置循环检测的元素为
//body,因为//body是所有网页都有的内容。 - 设置最多执行循环次数为15。
2. 无限循环设置
如果希望程序无限循环,直到指定的元素出现为止,可以通过以下方式设置:
修改循环类型:将循环类型设置为JavaScript命令返回值。
代码内容:在循环条件中输入以下代码,确保每次循环都继续执行:
javascriptreturn 1;这将使得程序不断循环,直到检测到指定元素为止。

检测页面内容并提取数据
在循环内部,添加条件判断操作,确保只有在页面加载出所需内容时才进行数据提取。具体步骤如下:
1. 添加条件判断
拖动条件判断操作:在任务流程中,将条件判断操作拖动到循环内部。
设置条件分支:
- 条件分支1:设置为“当前页面包含元素”,并输入目标元素的XPath路径。例如,
/html/body/div[2]/p。 - 条件分支2:设置为“无条件”,即当未检测到指定元素时执行。
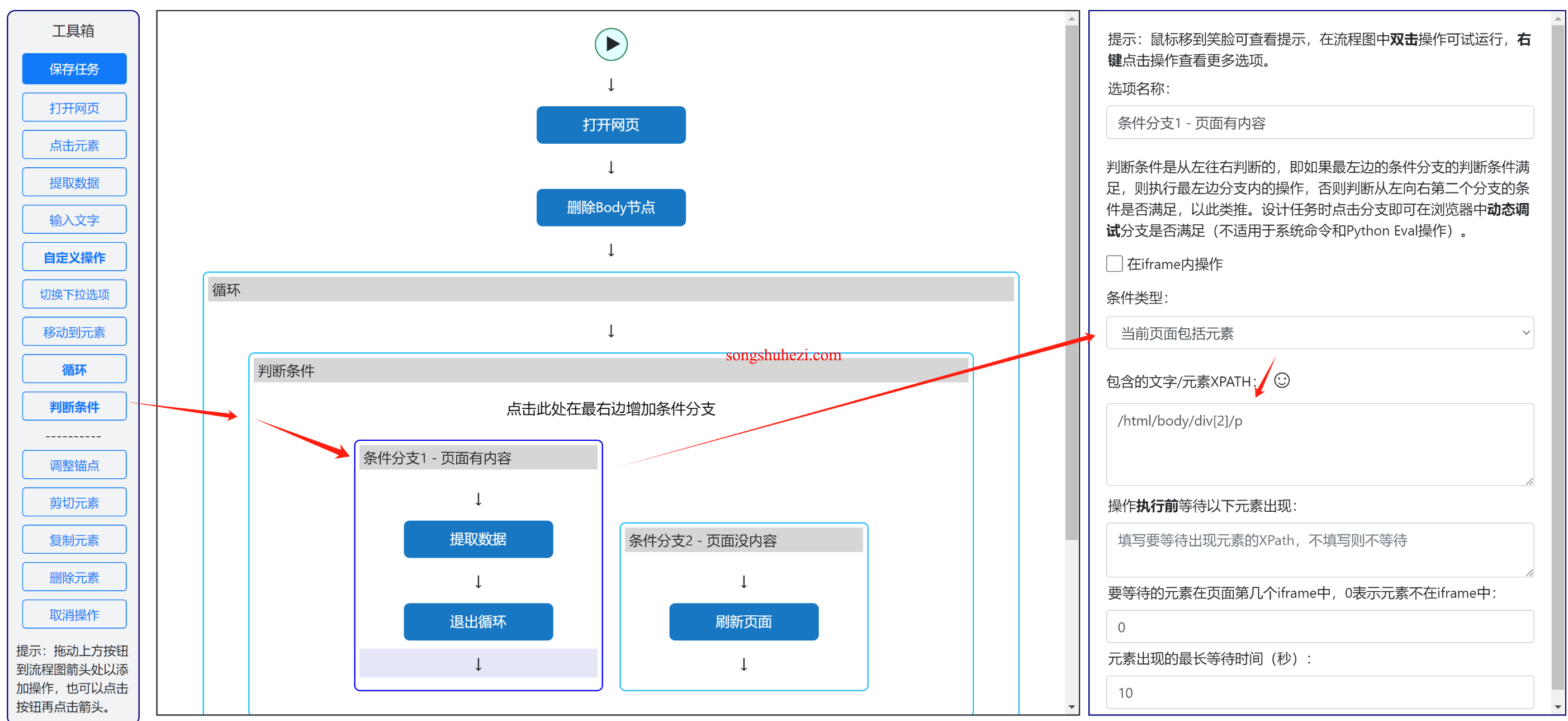
- 条件分支1:设置为“当前页面包含元素”,并输入目标元素的XPath路径。例如,
2. 设定提取数据和退出循环
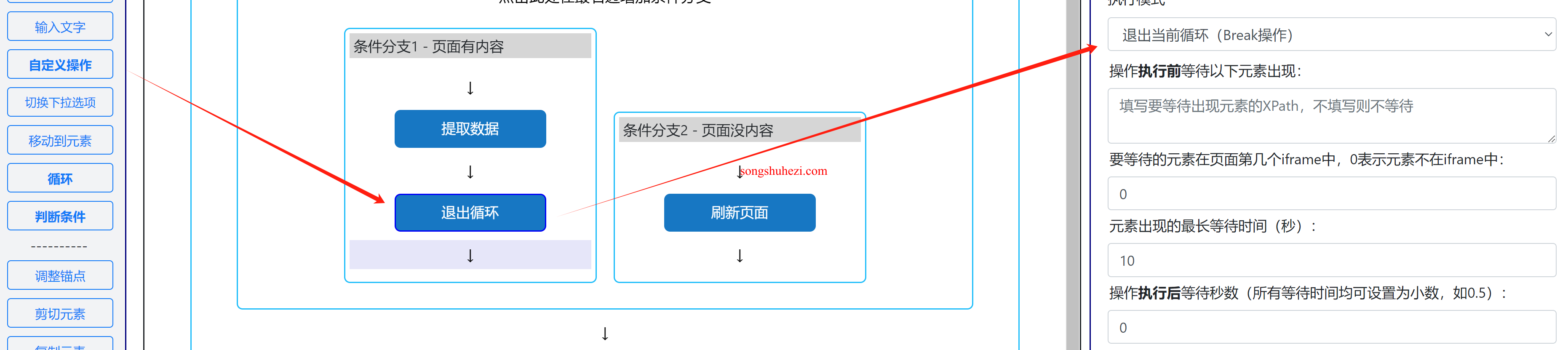
条件分支1内部操作:当检测到目标元素时,执行以下操作:
- 提取数据:通过提取操作获取目标元素的数据。
- 退出当前循环:在提取数据后,添加一个自定义操作,类型为“退出当前循环”,确保提取完成后程序停止循环。
3. 设定刷新页面操作
条件分支2内部操作:当未检测到目标元素时,执行页面刷新操作:
- 刷新页面:添加自定义操作,类型为“刷新当前页面”,确保页面在无法检测到元素时自动刷新,进行下一次检测。
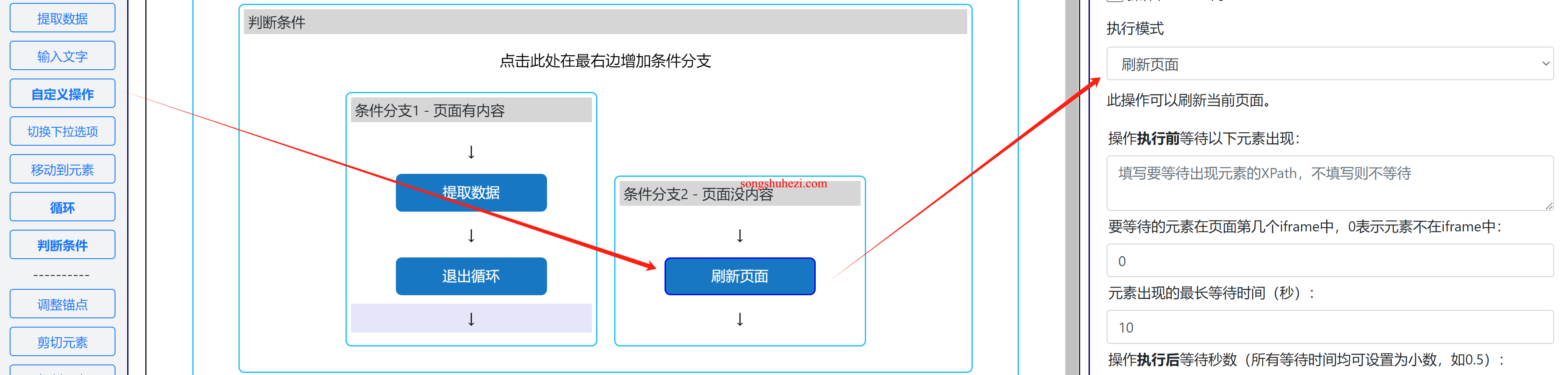
完整流程展示
- 设置循环操作:根据需要设置固定次数循环(最多15次)或无限循环。
- 添加条件判断:检测页面是否包含目标元素。
- 提取数据并退出循环:如果检测到目标元素,提取数据并退出循环。
- 刷新页面:如果未检测到元素,刷新页面并继续循环。
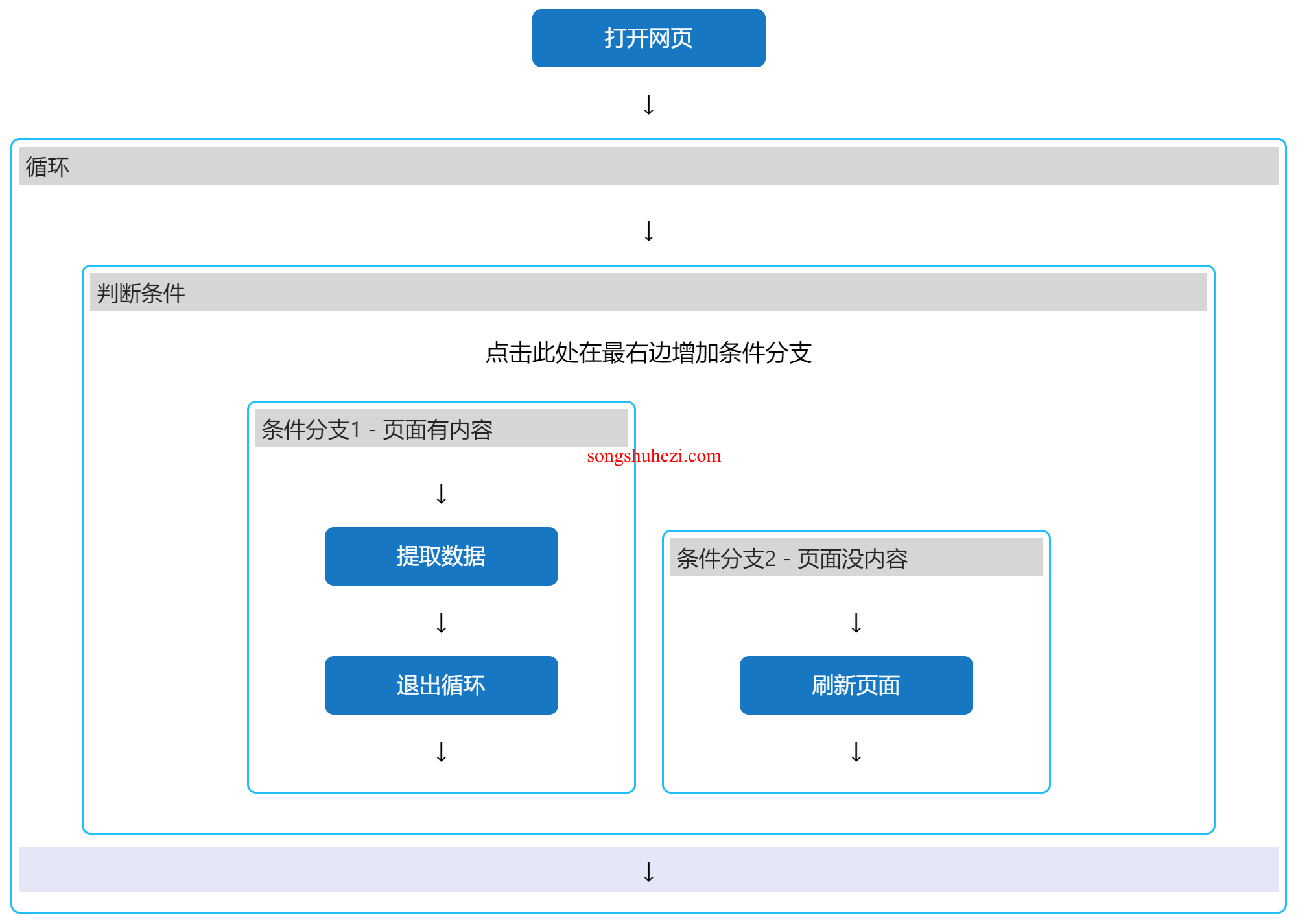
通过设置循环次数和页面内容检测,EasySpider能够高效处理页面加载不完全的问题。你可以根据任务需求选择固定次数循环或无限循环,并通过条件判断确保在页面内容加载完全后再提取数据,从而提高自动化任务的准确性。
想深入了解DeepSeek的核心玩法 扫描下方二维码加入微信群 
阅读全文
×
初次访问:反爬虫,人机识别
反爬虫抓取,人机验证,请输入验证码查看内容
请关注本站公众号回复关键字:“2024”,获取验证码。
微信搜索公众号:“RPA编程教程”或者“rpa1499” 或微信扫描上方二维码关注微信公众号



 RSS
RSS