






Web Scraper的下载、安装与使用
Web Scraper是一款免费且适用于普通用户的爬虫工具,能够通过简单的鼠标操作和配置来获取各种数据,例如知乎回答列表、微博热门、微博评论、电商网站商品信息、博客文章列表等。

环境需求
Web Scraper对环境的要求非常简单,只需要一台能联网的电脑和一个版本不低于31的Chrome浏览器。越新版本的浏览器越好,目前Chrome的版本已经超过120了。
安装过程
Chrome嘛,大家懂的都懂,所以在线安装可能需要魔法。但是别担心,我已经帮大家整理到网盘了,大家自行下载。
网盘链接:https://pan.quark.cn/s/4a6933a786b8
安装方式有两种:
在线安装方式:
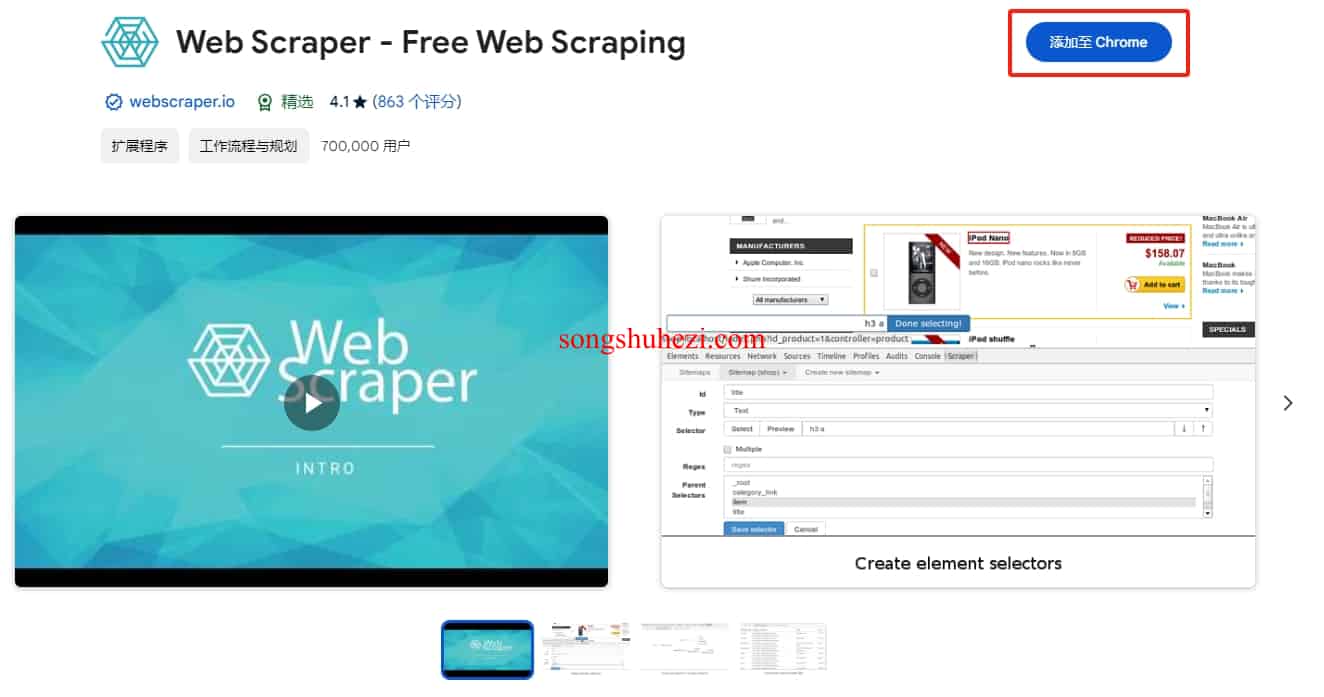
在Chrome应用商店搜索Web Scraper插件,并添加至Chrome浏览器。
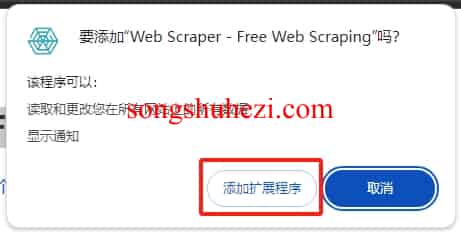
点击弹出框中的“添加扩展程序”。
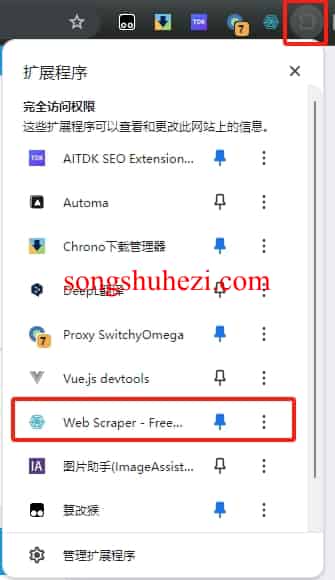
安装完成后,在顶部工具栏会显示Web Scraper的图标。
本地安装方式:
打开 Chrome,在地址栏输入
chrome://extensions/,打开Chrome浏览器扩展程序管理界面。
将下载好的扩展插件文件拖拽到扩展程序管理界面,点击“添加到扩展程序”即可完成安装。
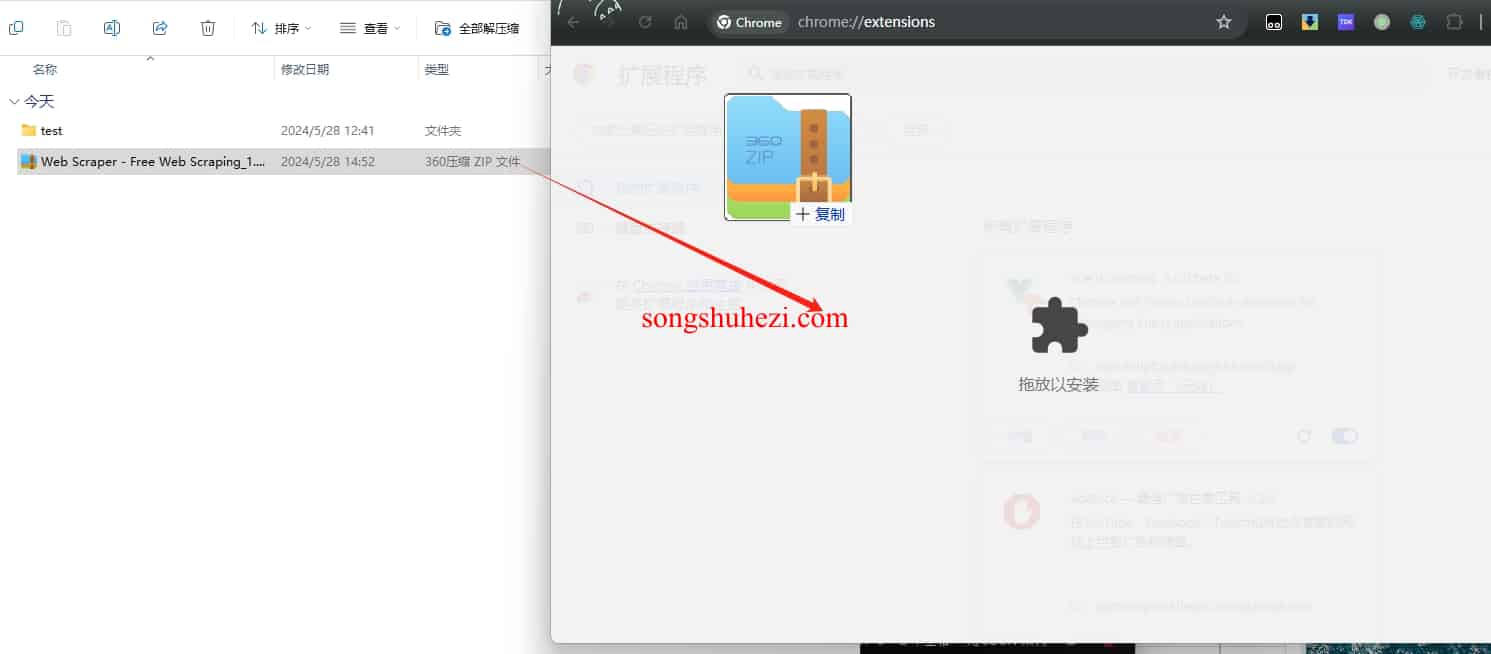
安装完成后,在顶部工具栏也会显示Web Scraper的图标。
安装完成后,你会在顶部工具栏看到 Web Scraper 的图标,点击即可开始使用。
原理及功能说明
我们使用Web Scraper一般是为了批量获取数据,因为手工方式太耗时费力,甚至根本无法完成。例如抓取微博热门前100条,或知乎某个问题的所有答案,这些任务都需要工具的帮助。
Web Scraper是一款界面简单、操作简单的工具,可以导出Excel格式的数据,不懂开发的用户也可以很快上手。
数据爬取思路
- 通过一个或多个入口地址,获取初始数据。例如一个文章列表页,或带有分页的列表页。
- 根据入口页面的某些信息,例如链接指向,进入下一级页面,获取必要信息。
- 根据上一级的链接继续进入下一层,获取必要信息(此步骤可以无限循环下去)。
对于那些需要批量获取网页数据的用户来说,它提供了一个简单且高效的解决方案。尤其是对于不懂编程的普通用户,通过Web Scraper可以快速上手,轻松完成数据爬取任务。所以,如果你有这方面的需求,不妨试试这款工具,相信你也会爱上它的。


反爬虫抓取,人机验证,请输入验证码查看内容
请关注本站公众号回复关键字:“2024”,获取验证码。
微信搜索公众号:“RPA编程教程”或者“rpa1499” 或微信扫描上方二维码关注微信公众号



 RSS
RSS