






Web Scraper:如何使用浏览器开发工具中的数据抓取工具
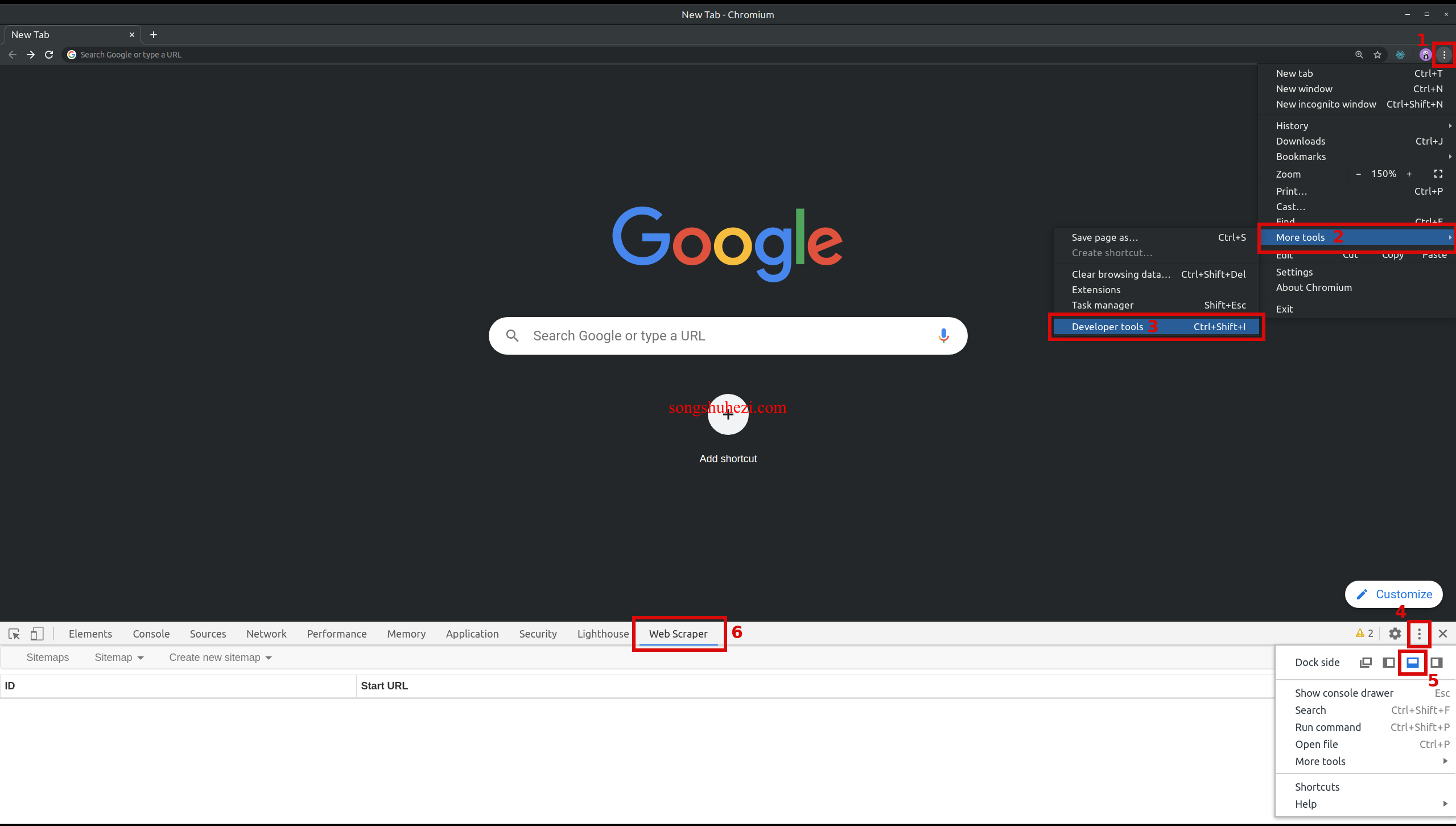
你知道吗?Web Scraper扩展其实是集成在浏览器的开发者工具中的,这个工具可以让你轻松抓取各种网页数据。首先呢,你需要打开Chrome浏览器中的开发者工具。你可以通过键盘快捷键来快速打开:
- Windows、Linux:Ctrl+Shift+I 或 F12
- Mac:Cmd+Opt+I
一旦打开开发者工具,你会在上方找到一个名为"Web Scraper"的标签。点击它,Web Scraper扩展就启动了。
开始抓取网站数据
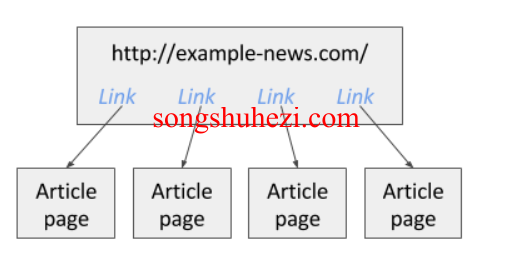
在你正式抓取数据之前,你得先打开你要抓取的网站。举个例子吧,假设你需要抓取一个新闻站点的文章链接,那你就需要先把这个新闻站点加载出来。
创建Sitemap
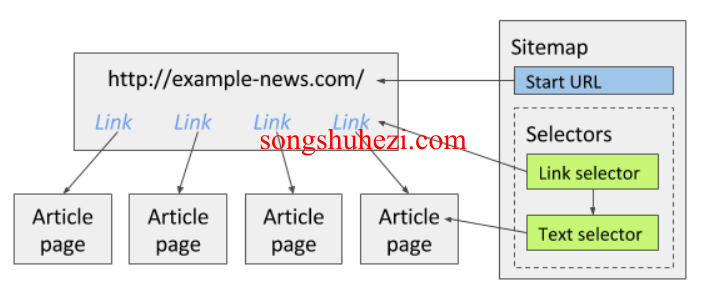
每次抓取数据前,你都需要创建一个新的Sitemap。简单来说,Sitemap 就是告诉Web Scraper从哪个URL开始抓取的指令。你只需指定一个开始URL,这就是Web Scraper将从哪一页开始工作。

当然了,你也可以同时指定多个开始URL,这样你就可以同时抓取多个不同的页面。举个例子吧,如果你想要抓取多个搜索结果,你可以为每个搜索结果页面创建一个单独的URL输入框,点击"+"号就能增加更多的URL输入框了。
如何指定URL范围
如果你要抓取的网站使用了带有数字编号的页面URL,你可以利用这个编号范围自动生成多个URL,而不必逐个链接去手动添加。比如说,你想抓取http://example.com/page/1到http://example.com/page/3这些页面。你可以使用如下格式的范围URL:
http://example.com/page/[1-3]
对于零填充的URL(比如 http://example.com/page/001 到 http://example.com/page/100),你可以这样设置:
http://example.com/page/[001-100]
另外,如果你想跳过某些URL,也可以指定增量范围,比如每10个页面跳一次:
http://example.com/page/[0-100:10]
这样,你将依次抓取 http://example.com/page/0、http://example.com/page/10、http://example.com/page/20 等等。
创建选择器
创建好Sitemap之后,下一步就是添加选择器。选择器就是告诉Web Scraper你希望从网站上提取哪些数据。它们的工作顺序是按照你在树状结构中设定的顺序来执行的。
假设你正在抓取一个新闻网站上的文章链接,那么你可以创建一个Link选择器,来提取页面上的所有文章链接。然后你可以在这个Link选择器下添加一个Text选择器,用来抓取每篇文章中的文本内容。
树状结构选择器的优势
Web Scraper 使用的是树状结构的选择器,这让整个过程更清晰易懂。你可以通过Element预览和Data预览功能来确保你选择的是正确的页面元素和数据。如果你对树状选择器的搭建有疑问,可以参考官方的选择器文档,了解更多核心选择器如Text选择器、Link选择器和Element选择器的使用方法。
检查选择器树
创建完选择器后,你可以在Selector Graph面板中查看整个选择器树的结构。如果有问题,你可以随时修改和调整。
开始抓取数据
当一切准备就绪,你就可以开始抓取数据了。在Scrape面板中,点击开始抓取的按钮。你可以根据需要调整请求间隔和页面加载延迟,以便适应不同网站的加载速度。
一旦抓取过程开始,Web Scraper会在一个新窗口中加载页面并提取数据。当数据抓取完成后,你会收到弹窗提示,所有数据都可以通过Browse面板查看,并可以通过Export data as CSV面板导出为CSV文件,方便后续分析。
请求间隔与页面加载延迟
- 请求间隔:每次请求之间的最短时间,适用于网站请求频率限制。
- 页面加载延迟:网页渲染完成后,Web Scraper开始执行选择器的延迟时间。
调整这些设置可以让抓取过程更稳定顺利。
我的感受
在我看来,Web Scraper 真的是一个非常方便的工具,不仅免费,还集成在浏览器的开发者工具中,不需要额外安装其他软件。它的树状选择器系统让人一目了然,不管是新手还是老手都能快速上手。而且嘛,支持范围URL的功能可以大大提高工作效率,特别是当你需要抓取分页数据的时候。
如果你是个喜欢自己动手抓取数据的人,那Web Scraper绝对是你不可错过的利器。


反爬虫抓取,人机验证,请输入验证码查看内容
请关注本站公众号回复关键字:“2024”,获取验证码。
微信搜索公众号:“RPA编程教程”或者“rpa1499” 或微信扫描上方二维码关注微信公众号



 RSS
RSS