






Web Scraper:如何使用Sitemap.xml链接选择器高效抓取网站数据
Sitemap.xml链接选择器 是Web Scraper中的一个功能,专门用于从网站的sitemap.xml文件中提取URL。这些sitemap.xml文件是网站为了帮助搜索引擎更好地索引网页而生成的,通常包含了网站的所有重要页面链接。使用该选择器,你可以遍历整个网站,无需设置复杂的分页或导航步骤。
使用Sitemap.xml链接选择器的好处
- 无需设置分页或导航:Sitemap.xml通常已经列出了所有网站的页面URL,因此你不需要额外设置复杂的分页或链接导航。
- 递归提取URL:如果sitemap.xml包含对其他sitemap.xml文件的引用,Web Scraper会自动递归提取这些子sitemap中的所有URL。
- 处理大规模站点:对于包含大量页面的站点,Sitemap.xml链接选择器可以有效简化抓取过程,尤其适用于大型电商、旅游或新闻网站。
Sitemap.xml链接选择器的配置选项
1. sitemap.xml URLs
你需要提供网站的sitemap.xml文件的URL列表。Web Scraper会根据这些URL提取网页链接。可以通过以下两种方式添加sitemap.xml的URL:
- 从robots.txt添加:点击“Add from robots.txt”按钮,Web Scraper会自动从
https://example.com/robots.txt文件中找到所有sitemap.xml链接。 - 手动添加:如果robots.txt中没有列出sitemap.xml文件,尝试访问
https://example.com/sitemap.xml手动检查该URL。
2. found URL RegEx(可选)
如果你只想抓取sitemap.xml文件中符合特定条件的URL,你可以在这个选项中添加正则表达式。例如,如果你只想抓取产品页面,你可以设置如下正则表达式:
/product/
这会限制抓取到包含/product/的URL,从而跳过其他非产品页面。
3. minimum priority(可选)
一些网站的sitemap.xml文件会对不同页面设置优先级,你可以通过这个选项只抓取优先级较高的页面。通过查看sitemap.xml文件中的优先级值,你可以决定是否需要在抓取中设置此值。
使用场景
1. 抓取整个网站
如果你需要抓取一个大型网站的所有数据,比如电商网站的产品信息、新闻网站的文章列表等,Sitemap.xml链接选择器是非常高效的选择。它可以遍历整个网站,而不需要你为每一个分页或导航设置复杂的选择器。
2. 只抓取特定页面
有些网站的sitemap.xml文件包含多种页面,比如产品页、分类页、关于我们页等。你可以通过正则表达式或页面优先级来限制抓取范围。例如,在电商网站的sitemap.xml文件中,你可以使用正则表达式 product 来确保只抓取产品页面,而跳过其他类型的页面。
处理大站点的策略
Sitemap.xml文件有时会非常大,可能包含成千上万个页面。如果sitemap.xml文件超出了Web Scraper的下载限制,可以考虑以下解决方案:
- 分割sitemap.xml文件:将站点的sitemap.xml文件拆分成多个较小的文件,每个文件只包含部分URL,这样可以避免超过抓取限制。
- 使用Web Scraper Cloud:对于大规模数据抓取,建议使用Web Scraper的云服务,这样可以更好地处理大量数据。
如何限制抓取只包含特定数据的页面
如果你只需要抓取某些页面(比如只抓取产品页面而忽略其他页面),可以通过以下几种方法进行限制:
1. 使用正则表达式
你可以在found URL RegEx选项中设置正则表达式。假设所有产品页面的URL都包含/product/,你可以设置如下正则表达式:
/product/
这样,只有符合这个条件的URL才会被抓取,其他页面会被跳过。
2. 设置页面优先级
如果sitemap.xml文件中对不同类型的页面设置了优先级,你可以根据这个优先级来限制抓取的页面。例如,优先抓取产品页面或高优先级页面,忽略低优先级的页面。
3. 使用包装元素选择器
如果正则表达式或优先级设置都不能满足你的需求,可以使用包装元素选择器。此方法适用于所有网站,通过选择每个页面中独特的元素来限制抓取。例如,如果只有产品页面有 h1.product-title 这样的标签,可以设置如下选择器:
body:has(h1.product-title)
这样,只有包含这个特定元素的页面才会被抓取,其他页面则会被跳过。
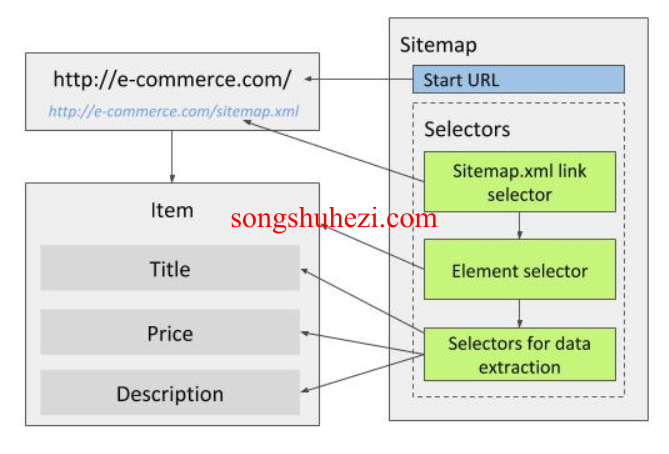
示例:抓取电商网站的产品信息
- 配置sitemap.xml URL:在Web Scraper中,输入电商网站的
sitemap.xml文件地址。 - 设置正则表达式:在
found URL RegEx选项中,输入/product/来限制只抓取产品页面。 - 添加子选择器:使用文本选择器提取产品页面中的具体数据,例如产品标题、价格、描述等。
最后感受
Sitemap.xml链接选择器可以大大简化抓取网站的工作流程,尤其是对于那些页面结构复杂、包含分页和多级导航的网站来说。通过直接从sitemap.xml文件中提取URL,你可以跳过很多不必要的步骤,快速遍历整个网站。此外,配合正则表达式和页面优先级设置,你可以精准地筛选出所需的数据页面,避免抓取无关内容。
对于大规模的网站数据抓取,Sitemap.xml链接选择器是必备的利器。如果你想高效地抓取整站数据,不妨试试这个强大的功能!


反爬虫抓取,人机验证,请输入验证码查看内容
请关注本站公众号回复关键字:“2024”,获取验证码。
微信搜索公众号:“RPA编程教程”或者“rpa1499” 或微信扫描上方二维码关注微信公众号



 RSS
RSS