






Web Scraper:如何导出抓取到的数据
Web Scraper 提供了多种数据导出选项,支持将抓取到的数据导出为CSV、XLSX 和 JSON 格式。用户可以手动下载数据,也可以通过API或自动化工具将数据导出到云存储服务(如Dropbox、Google Sheets或Amazon S3)。此外,Web Scraper Cloud进一步增强了导出功能,支持更大规模的数据集处理。
数据导出方式
1. 从Web Scraper浏览器扩展导出数据
使用浏览器扩展时,你可以通过以下方式手动下载抓取的数据:
在Sitemap菜单下选择“导出数据为CSV”。
在抓取任务运行时也可以实时下载数据。
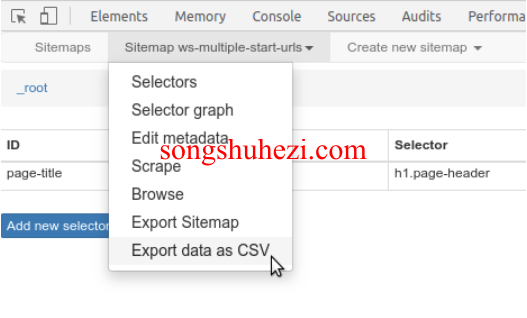
注意:目前Web Scraper扩展仅支持CSV和XLSX格式的导出,JSON格式将在未来的更新中加入。
2. 从Web Scraper Cloud导出数据
在Web Scraper Cloud中,你可以从任务或Sitemap部分下载已抓取的数据。导出可以在抓取任务运行时或任务完成后进行,支持三种格式:CSV、XLSX 和 JSON。
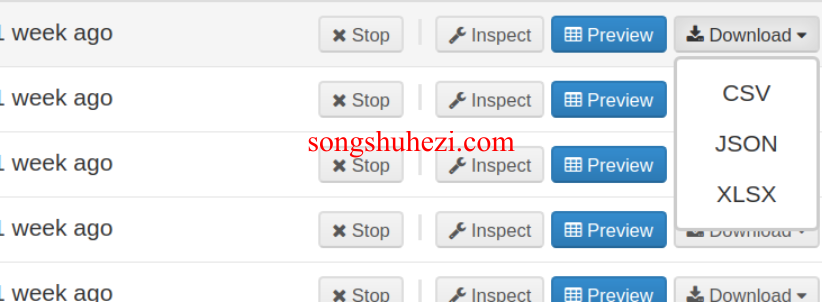
自动化数据导出
Web Scraper Cloud支持自动化数据导出,用户可以将抓取到的数据自动导出到以下云服务:
- Dropbox
- Google Sheets
- Amazon S3
数据将被导出为CSV格式,自动保存到以下路径:
- Dropbox:
Apps/Web Scraper - Google Sheets:
Google Drive/Web Scraper - S3:
bucket/web-scraper
通过API导出数据
Web Scraper Cloud还支持通过API以CSV或JSON格式下载抓取到的数据。这为开发人员提供了更灵活的方式来自动化数据下载和处理。
数据格式及限制
1. XLSX格式
每个单元格中的字符数量限制为32767个字符,超过部分将被截断。
每张表最多可以包含100万行数据。如果数据超过100万行,导出时将分成多个子表。
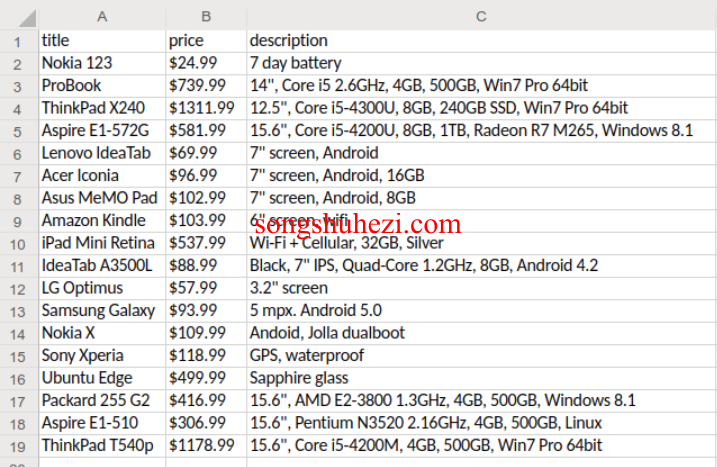
2. JSON格式
JSON文件格式为每行一个JSON记录,行内的换行符将被转义为
\n。注意:文件并不是一个完整的JSON数组,每条记录是独立的。解析文件时应逐行读取,而不是一次性将整个文件作为JSON对象处理。

3. CSV格式
CSV文件采用RFC 4180标准格式,具体特点如下:
逗号分隔值,内容使用双引号包裹,双引号字符在文本中会被双倍转义为
""。行与行之间使用CR+LF (
\r\n)作为分隔符。CSV文件以BOM(字节顺序标记)U+FEFF字符开头,提示文件为UTF-8编码。
注意:Microsoft Excel有时会错误解析标准的CSV文件,建议使用LibreOffice Calc打开CSV文件。

使用Excel导入CSV文件
如果Microsoft Excel无法正确读取CSV文件,可以按照以下步骤导入数据:
新建一个空文件。
在数据选项卡中,选择“从文本/CSV导入”。
选择CSV文件,设置导入选项为:UTF-8编码、逗号分隔符、不检测数据类型。
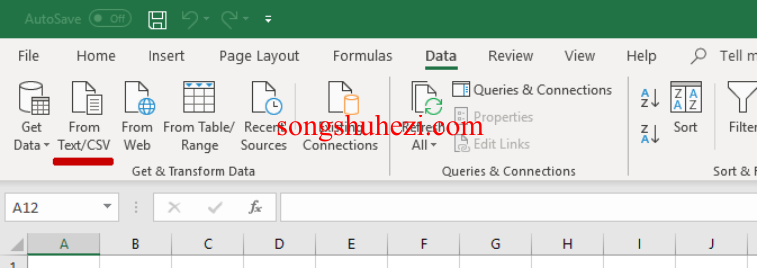
通过正确设置导入参数,可以避免数据格式错误或乱码问题。
最后感受
Web Scraper的多种数据导出功能 为用户提供了灵活、便捷的数据处理方式。无论是通过浏览器扩展手动导出,还是利用Web Scraper Cloud实现自动化导出,用户都可以根据需求选择合适的导出格式和方法。如果你需要处理大规模的数据集或希望实现数据导出的自动化,Web Scraper Cloud无疑是最佳选择!


反爬虫抓取,人机验证,请输入验证码查看内容
请关注本站公众号回复关键字:“2024”,获取验证码。
微信搜索公众号:“RPA编程教程”或者“rpa1499” 或微信扫描上方二维码关注微信公众号



 RSS
RSS