






DeepSeek V3的差异化创新点
最近DeepSeek真是刷爆了各大平台,尤其是和AI相关的博主,几乎都在介绍它。DeepSeek的热度蹭蹭往上涨,其他国产AI大模型厂商估计都羡慕得眼红了吧。毕竟,DeepSeek背后可是幻方量化这家大佬公司,师出名门,实力不凡。那么,这个大模型到底有啥特别之处呢?
要说一个大模型牛不牛,主要看三个方面:网络架构的创新、训练和推理的底层优化、以及强化学习路径的突破。而DeepSeek在这些方面都有亮眼表现,接下来我们就一一拆解。
网络架构创新:Attention机制的升级
大家都知道,Transformer架构的核心在于Attention机制,它通过计算token之间的相似度来提取特征,效果那是吊打传统架构。不过,Attention也有个致命缺点——时间和空间复杂度高,达到了 O(n2)O(n2)。为了解决这个问题,DeepSeek在Attention机制上做了改进,提出了 Multi-Head Latent Attention。
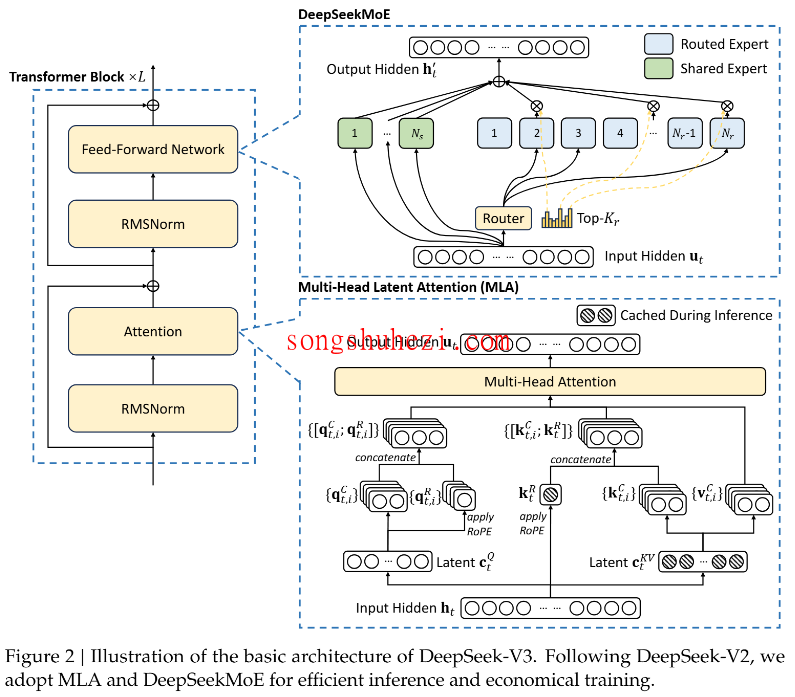
简单来说,DeepSeek在Attention部分引入了“latent”概念。它通过对输入hidden层进行线性映射,将高维度降到低维度,然后分别对Query和Key进行独立的线性变换,生成latent向量。接着,再进行常规的Attention操作,比如位置旋转编码(RoPE)和多头分割。虽然理论上复杂度还是 O(n2)O(n2),但因为维度降低了,实际耗时大幅减少。
FFN模块:MOE架构的独特优化
DeepSeek在FFN模块中采用了MOE(专家混合)架构,并且给出了自己的创新点。MOE的核心在于选择性激活不同的“专家”(exports)。DeepSeek将这些专家分为两类:绿色专家永远激活,蓝色专家通过Router选择性激活。这样一来,每个问题都可以由多个专家同时计算,输出各自的结果。
为了避免某些专家被过度使用,DeepSeek引入了负载均衡机制。通过一种额外的loss函数,鼓励每个专家在不同的序列上均匀工作。具体来说,它会计算每个序列的平均负载和不均衡程度,然后对使用频率过高的专家进行降权,从而实现更合理的资源分配。
Multi-Token Predict:加速推理的新思路
传统的Transformer模型在推理时是逐个输出token,而DeepSeek则采用了 Multi-Token Predict(MTP) 模块,提升了推理速度。这个思路其实有点类似于早期的word2vec模型,它通过一个token预测多个context,从而获取更多的信息。
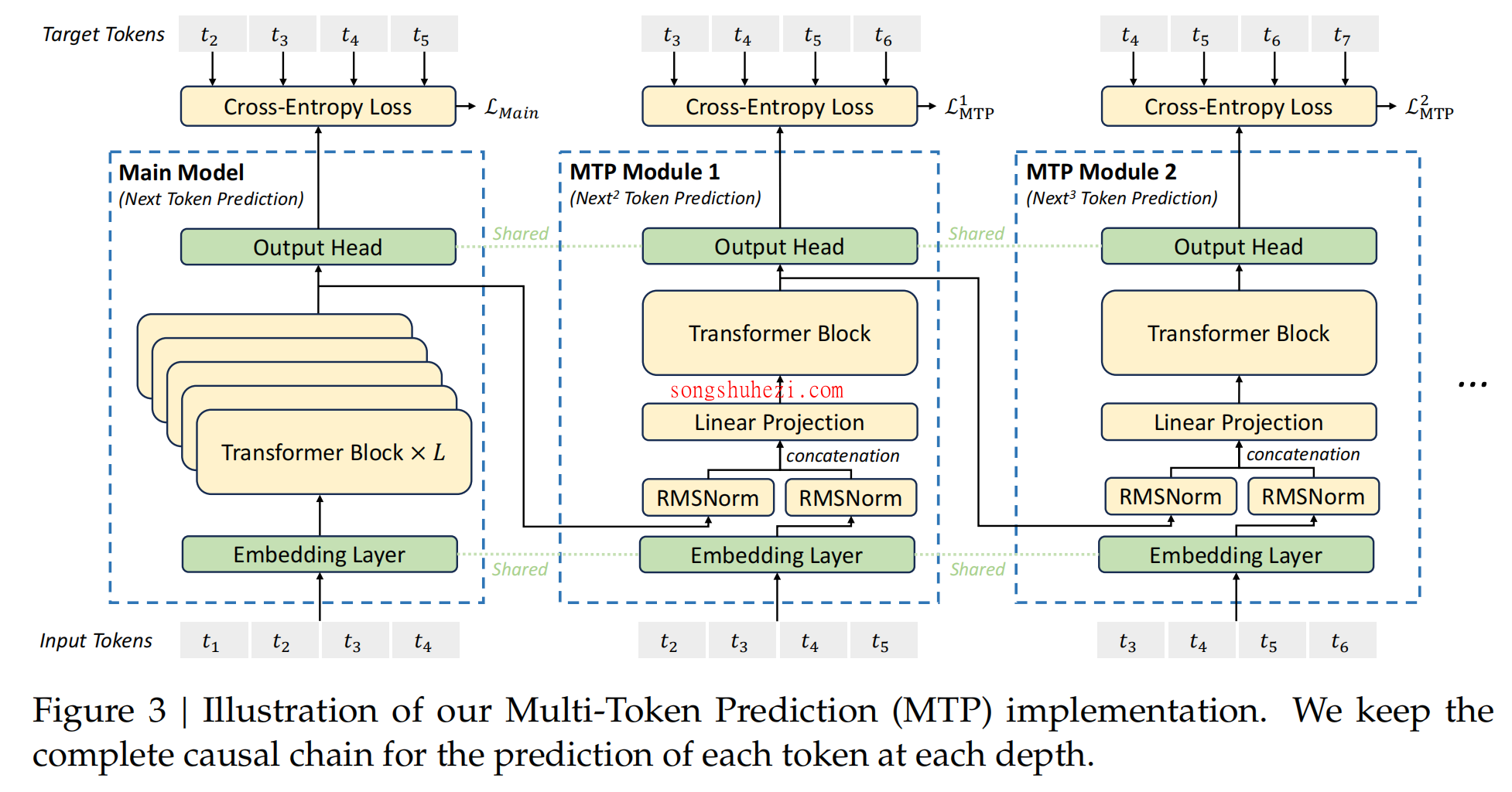
具体到DeepSeek的实现上,训练阶段会引入额外的MTP模块,逐层预测后续的token,并将这些loss用于反向传播更新主模型的参数。这样一来,每个token的表示都会包含更多的上下文信息,避免了传统方法只关注下一个token的局限性。虽然这个思路并非DeepSeek首创,但其对模型学习效率的提升确实显著。
FP8量化:存储与计算的平衡
大模型的参数量巨大,显存和计算资源的消耗也随之增加。为了解决这个问题,DeepSeek采用了FP8分块量化技术,将数据存储从FP32或FP16降到FP8,从而大幅降低显存占用。
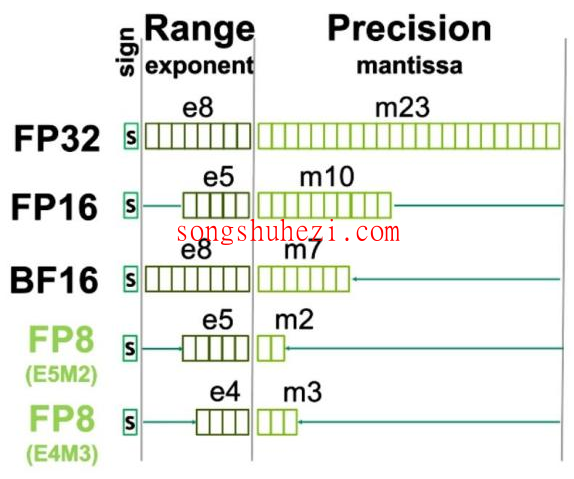
不过,FP8的精度较低,可能会导致数值下溢。为此,DeepSeek对矩阵进行了行列分块,并在块内部使用FP8计算,再通过CUDA核心进行反量化。这样做既能控制误差,又能充分利用FP8的存储优势。
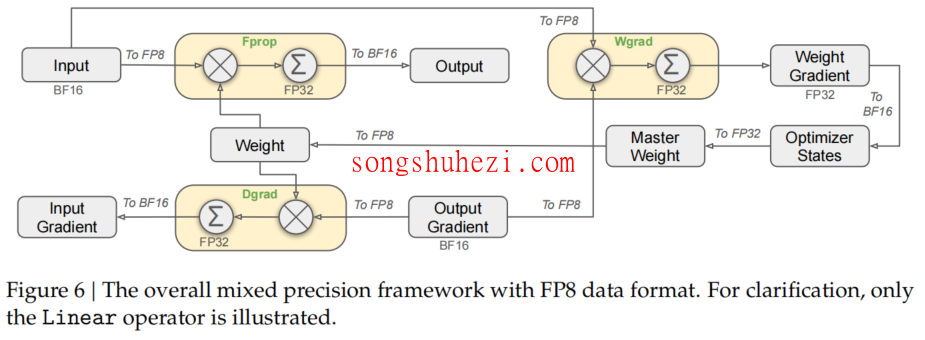
据说,DeepSeek V3的671B参数用FP8存储后大小约700GB,而如果用FP16存储,至少需要翻两到三倍的空间。
并行计算:DualPipe框架的高效设计
大模型的训练和推理少不了并行计算,DeepSeek在这方面也有自己的独特之处。它设计了一种名为 DualPipe 的框架,让计算和通信可以并行进行,互不等待,从而显著提升了利用率。

传统的单向流水线通常会产生较多的“气泡”(Pipeline Bubble),导致资源浪费。而DualPipe通过双向流水线设计,同时从两端输入微批次数据,并将每个批次进一步划分成更小的块。这种方式让计算和通信高度重叠,大幅减少了流水线中的空闲时间。

举个例子,就像餐厅后厨做菜一样,分拣、择菜、洗菜、切菜等环节可以无缝衔接,而不是等所有番茄都分拣完了再择菜。这样一来,每个环节的效率都能提升不少。
结语
DeepSeek V3的确是一款亮点满满的大模型。无论是网络架构的创新、训练优化的细节,还是推理效率的提升,每一项改进都直击痛点。尤其是像Multi-Token Predict和FP8量化这样的技术,不仅提升了性能,还降低了资源消耗。
我的感觉是,如果你对大模型的底层原理感兴趣,DeepSeek绝对值得深入研究。它的每一项设计都体现了对效率和效果的追求,堪称大模型领域的一股清流。

反爬虫抓取,人机验证,请输入验证码查看内容
请关注本站公众号回复关键字:“2024”,获取验证码。
打开微信扫描上方二维码关注微信公众号



 RSS
RSS