






全面比较 DeepSeek-R1 与 OpenAI O3-mini
在 AI 模型领域,OpenAI 和 DeepSeek 都是响当当的名字。最近,OpenAI 推出了全新的 O3-mini 模型,而 DeepSeek 的 R1 模型也早已凭借强大的性能在市场上占有一席之地。那么,这两款模型在实际表现上究竟如何?今天我们就来详细对比一下,看看谁更适合你的需求。
全局表现:O3-mini 略胜一筹
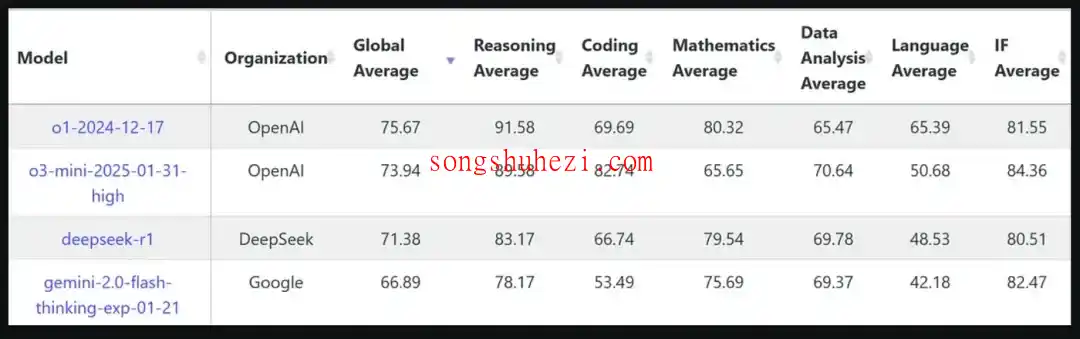
根据多项基准测试数据,O3-mini 的全局平均得分稍微领先于 DeepSeek-R1,分别为 73.94 和 71.38。虽然差距不算大,但在多任务处理的整体表现上,O3-mini 确实略胜一筹。
推理能力:O3-mini 的强项
在推理任务中,O3-mini 的表现非常亮眼,得分高达 89.58,而 DeepSeek-R1 为 83.17。这意味着 O3-mini 在理解复杂问题、分析信息并得出结论方面具有更强的能力。如果你的工作需要频繁依靠 AI 进行逻辑推理,O3-mini 是一个更好的选择。
编码能力:O3-mini 碾压式优势
如果你是开发者或需要处理大量编程任务,那 O3-mini 的表现会让你眼前一亮。它在编码任务上的得分高达 82.74,而 DeepSeek-R1 仅为 66.74,差距显著。无论是理解编程概念还是解决实际编码问题,O3-mini 都展现了卓越的能力。
数学能力:DeepSeek-R1 的主场
不过,DeepSeek-R1 在数学任务上的表现则更为突出。它的得分为 79.54,而 O3-mini 仅为 65.65。如果你的需求更多集中在数学推理和数值计算上,DeepSeek-R1 无疑是更好的选择。
数据分析:O3-mini 稍占优势
在数据分析任务中,O3-mini 的得分为 70.64,比 DeepSeek-R1 的 69.78 略高一点点。虽然优势不明显,但这也表明 O3-mini 在处理和解释数据集方面稍胜一筹。
语言能力:O3-mini 表现更稳定
在语言任务上,O3-mini 的得分为 50.68,而 DeepSeek-R1 为 48.53。虽然两者差距不大,但 O3-mini 的表现更为稳定。如果你需要处理自然语言相关的任务,O3-mini 会是更好的选择。
特殊任务表现:O3-mini 更胜一筹
在一些特殊任务上,例如 NYT Connections(谜题解答)和 Codeforces 编程比赛,O3-mini 的表现显然更为优异。例如,在 NYT Connections 基准测试中,O3-mini 的得分为 72.4,而 DeepSeek-R1 仅为 54.4。这表明 O3-mini 在解决复杂问题和挑战性任务上更具优势。
校准能力:DeepSeek-R1 更可靠
虽然 O3-mini 在准确性上表现更好,但其校准误差较高,得分为 93.2,而 DeepSeek-R1 的校准误差为 81.8。这意味着 DeepSeek-R1 的预测可信度更高。如果你更看重模型的稳定性和可靠性,DeepSeek-R1 是更好的选择。
部署与成本:DeepSeek-R1 的开源优势
DeepSeek-R1 的一大亮点在于它完全开源,支持本地部署。这对于注重数据隐私的用户来说是一个巨大的优势。而 O3-mini 则是封闭的,无法像 DeepSeek-R1 那样灵活部署。此外,在 API 成本上,DeepSeek-R1 也更具性价比,每百万输入令牌的价格为 0.14 美元,而 O3-mini 为 0.55 美元。
最后
如果你需要一款全能型的 AI 模型,尤其是在推理和编码任务上,O3-mini 无疑是一个更好的选择。不过,如果你的需求更多集中在数学推理、数据隐私或成本控制上,DeepSeek-R1 则更具吸引力。两款模型各有千秋,具体选择还是得根据你的实际需求来定。

反爬虫抓取,人机验证,请输入验证码查看内容
请关注本站公众号回复关键字:“2024”,获取验证码。
打开微信扫描上方二维码关注微信公众号



 RSS
RSS