






使用DeepSeeK和RAGFlow搭建本地知识库
你有没有在网上用过DeepSeek?作为一款强大的知识库管理工具,它能帮你从大量信息中提取和生成高质量的回答,但如果你对数据隐私比较敏感,或者处理的文件多得让网页版DeepSeek束手无策,那你可能会遇到一些难题。今天,我就带大家探讨一下,如何通过DeepSeek和RAGFlow本地部署,搭建属于你自己的个人知识库。
为什么不直接用网页版DeepSeek?
说到网页版的DeepSeek,它确实是个非常方便的工具,尤其是在快速获取信息时,但它也有一些你可能不喜欢的地方。最直接的就是隐私问题。所有的文件和数据都要上传到DeepSeek的服务器,万一你的数据特别敏感,那可就没办法保证100%的安全性了。
再有就是上传文件的数量限制。如果你有成堆的文件,比如一些专业的资料,网页版可能没办法一次性处理这么多数据。而且,上传、删除、修改文件的过程也比较繁琐,每次操作都得重新上传,感觉有点麻烦。
那怎么解决这些问题?
要解决这些限制,最简单的方法就是选择本地部署DeepSeek和RAGFlow。通过本地部署,你可以完全避免数据上传到外部服务器,确保了隐私性;同时,可以自由地上传和管理大量文件,打造一个更加个性化的知识库。
什么是RAG技术?
RAG(Retrieval-Augmented Generation)技术,说得通俗一点,就是模型先从外部知识库里检索相关的内容,再结合这些信息来生成更加准确的答案。其实就像开卷考试,你不需要死记硬背,只要知道从哪里翻资料就行。这种方法不仅能节省时间,还能提高回答的准确度。
RAG的工作流程大致是这样:
- 检索(Retrieval):从你的知识库中检索出相关内容。
- 增强(Augmentation):将检索到的内容和用户输入结合,形成更完整的上下文。
- 生成(Generation):基于增强后的内容生成答案。
这样的技术可以帮助DeepSeek更加智能地利用知识库,实时生成准确且相关的答案。
什么是Embedding?为什么它很重要?
Embedding技术其实就是把自然语言转化成计算机可以理解的高维向量。你可以把它想象成是把“蟹堡王”和“比奇堡”放到一个向量空间里,虽然这两者不完全相同,但它们在语义上非常接近。而“深度学习”则会和它们相距很远。通过Embedding,系统能更好地理解用户输入的语义,找到最相关的内容来生成答案。
1、配置Ollama
第一步:安装 Ollama
Ollama 是开源 AI 工具中的一颗璀璨明珠!借助它,你可以在自己的电脑上运行像 GPT-4 和 DeepSeek 等强大的 AI 模型,简直比拿个超级计算机还方便!
前面我写过各个系统的安装教程,大家可以看一看:
第二步:配置环境变量
安装完成后,配置一下环境变量。具体步骤如下:
打开 Windows 设置,选择【系统】->【关于】,点击【高级系统设置】。

在弹出的窗口中,点击【环境变量】按钮。
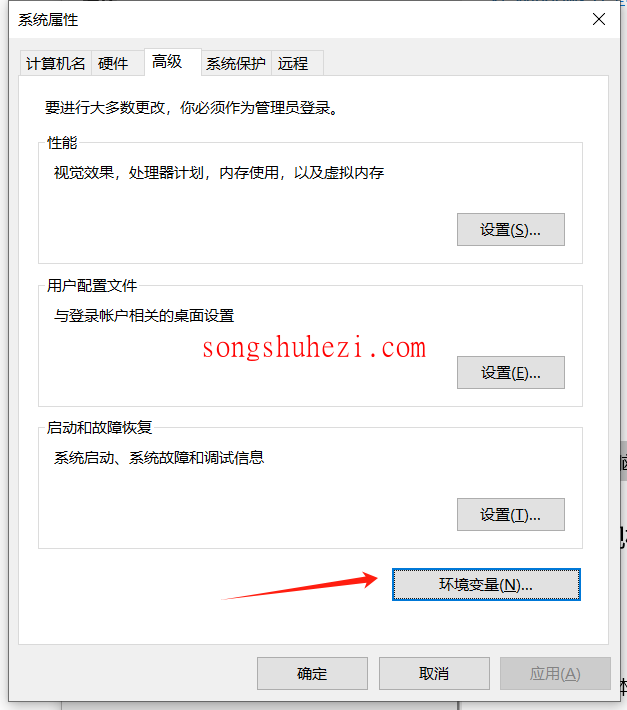
在系统变量部分,点击【新建】,然后输入以下两个变量:
OLLAMA_HOST:设置为
0.0.0.0:11434(这是 Ollama 默认的模型下载地址)。OLLAMA_MODELS:设置为你存放模型的路径,例如
E:\study\ollama。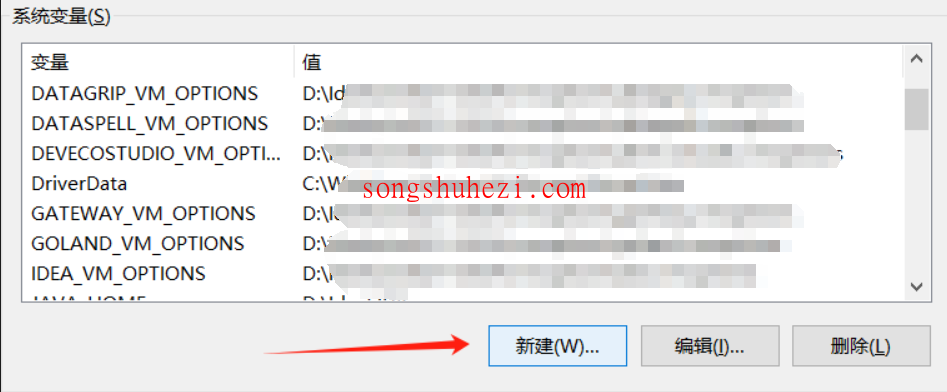
配置好后,点击【确定】即可。
第三步:安装并运行模型
安装好 Ollama 后,我们可以通过命令行下载并运行模型。打开命令提示符(按 Win+R 输入 cmd),然后输入以下命令来安装 DeepSeek r1 模型:
bash
ollama run deepseek-r1:7b

下载过程可能需要些时间,耐心等待即可。
安装完成后,通过以下命令查看是否成功安装:
bash
ollama list

接下来运行模型,输入命令:
bash
ollama run deepseek-r1:7b

你可以开始提问或者与模型进行互动啦!
2、下载 RagFlow:建议选择方法二
方法一:使用 Git 下载源代码
首先,安装 Git,安装过程只需要一键点击“下一步”即可。如果你尚未安装 Git,可以从 Git 官网 获取。
安装好 Git 后,需要配置用户名和邮箱。打开 Git Bash,输入以下命令:
bash
git config --global user.name "Your Name"
git config --global user.email "your_email@example.com"
接下来,打开 Git Bash 或者命令行工具,输入以下命令来下载 RagFlow 源代码:
bash
git clone https://github.com/infiniflow/ragflow.git
如果下载过程中遇到网络问题,可以尝试以下命令清除代理设置:
bash
git config --global --unset http.proxy
git config --global --unset https.proxy
如果问题依旧,可以尝试修改 HTTP 版本:
bash
git config --global http.version HTTP/1.1
方法二:直接下载 RagFlow 源代码
这里我已经把源码整理到网盘了,获取链接我放到后面了,大家自行下载就好。下载完成后解压即可。

下载完源代码后需要来配置下Docker,接下来跟着下面的步骤来安装Docker。
安装 Docker
如果你还没有安装 Docker,首先需要进行安装。这里我已经为大家准备好了安装包,大家自行下载安装就好。

网盘链接:https://pan.quark.cn/s/9fc946bf7bed
Docker 支持 Windows 10/11 64 位的 Pro、Enterprise 或 Education 版本,且要求硬件支持虚拟化技术(例如 Intel VT-x 或 AMD-V)并且内存至少为 4 GB。
第一步:检查虚拟化设置
按
Ctrl + Shift + Esc打开任务管理器,点击【性能】标签,查看“虚拟化”是否为“已启用”。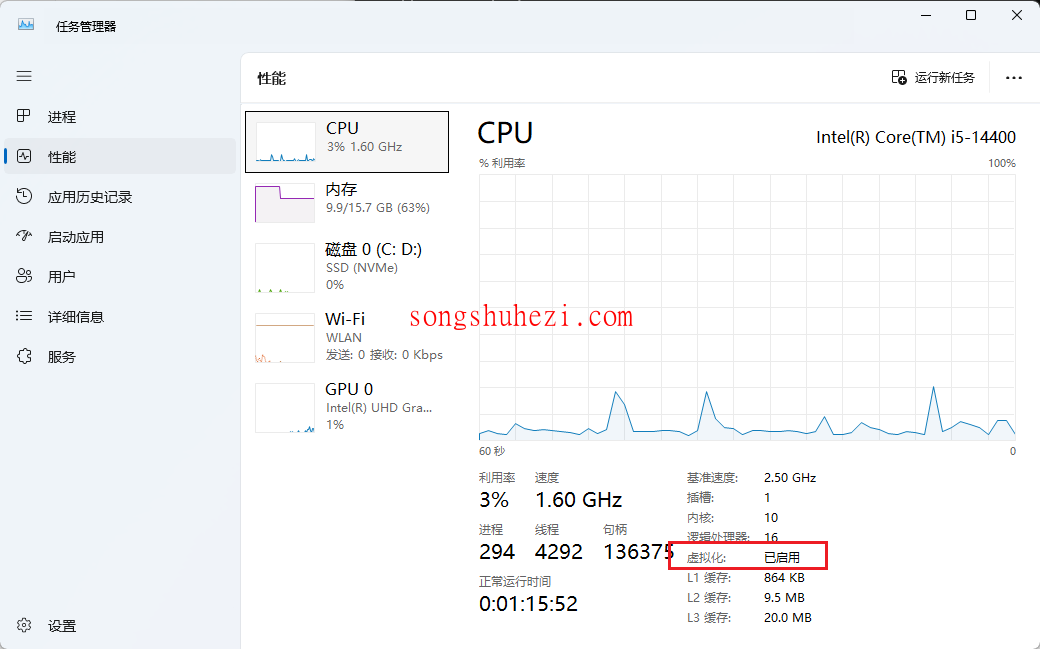
如果没有启用虚拟化技术,需要进入 BIOS 设置并启用它。一般来说,开机时按
F2或Del键进入 BIOS 设置,找到虚拟化相关选项并启用。保存后重启。
第二步:安装 Docker
下载并安装 Docker Desktop:这里我已经把源码整理到网盘了,获取链接我放到后面了,大家自行下载就好。

安装完成后,启动 Docker Desktop。如果第一次运行 Docker,可能会提示你安装 Windows 子系统 Linux 2(WSL 2)。
第三步:启用 WSL 2
打开 PowerShell,运行以下命令来检查是否已安装 WSL:
bash
wsl -l
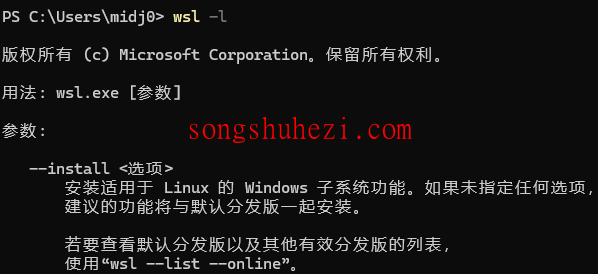
如果没有安装 WSL,可以通过以下命令来安装:
bash
wsl --install
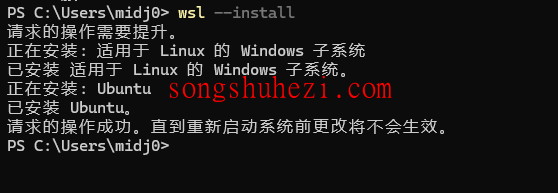
按照提示完成安装后,重启你的计算机。
第四步:配置 Docker 以支持 WSL 2
安装后不用登陆不用设置任何东西,全部跳过。确保在 Docker Desktop 设置中启用了 WSL 2 后,重新启动 Docker 即可开始使用。

第五步:配置 docker 镜像源
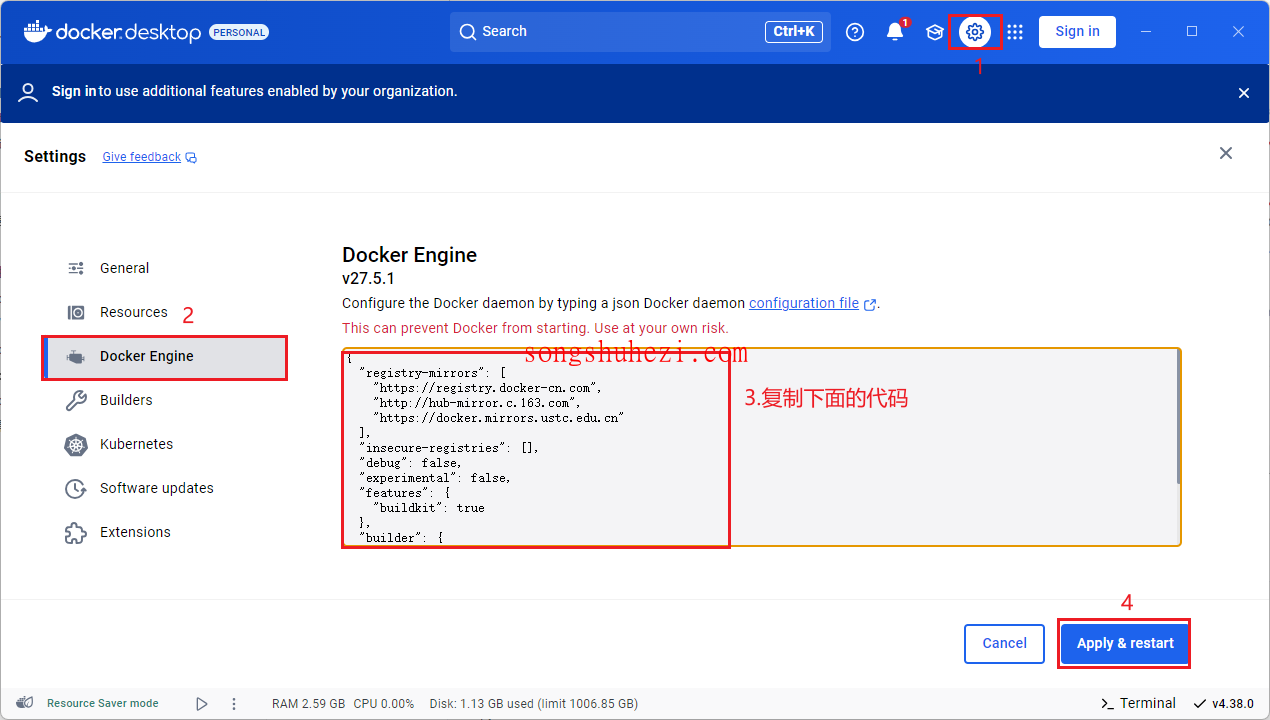
javascript
{
"registry-mirrors": [
"https://registry.docker-cn.com",
"http://hub-mirror.c.163.com",
"https://docker.mirrors.ustc.edu.cn"
],
"insecure-registries": [],
"debug": false,
"experimental": false,
"features": {
"buildkit": true
},
"builder": {
"gc": {
"enabled": true,
"defaultKeepStorage": "20GB"
}
}
}
第六步:进入 Docker 文件夹,启动 RagFlow 服务
下载并解压 RagFlow 后,进入解压后的文件夹,找到 docker 文件夹。使用 Docker 启动 RagFlow 服务。
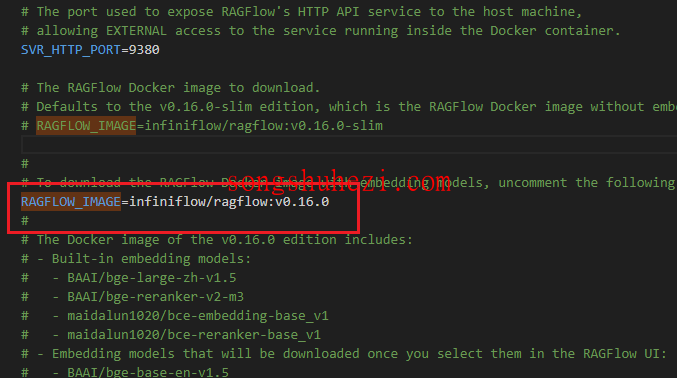
在启动服务前,首先需要修改 docker/.env 文件中的 RAGFLOW_IMAGE 变量。将其设置为:
bash
RAGFLOW_IMAGE=infiniflow/ragflow:v0.16.0

接下来我们开始部署 docker 镜像,按住 win+R 键,输入 powershell,点击回车。
之后输入 cd+刚刚下载的ragflow文件夹下的docker路径,输入docker compose -f docker-compose.yml up -d按回车。Docker会开始加载Ragflow镜像。这个过程大概需要15分钟,耐心等一下。
bash
docker compose -f docker-compose.yml up -d
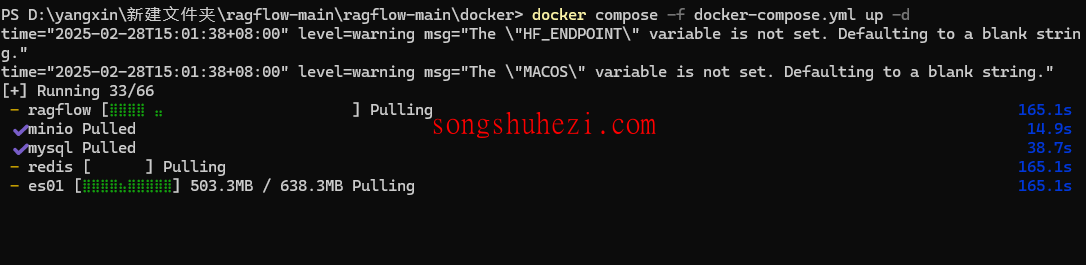
安装完成后。在浏览器地址栏输入 localhost:80,就能打开Ragflow的登录页面。
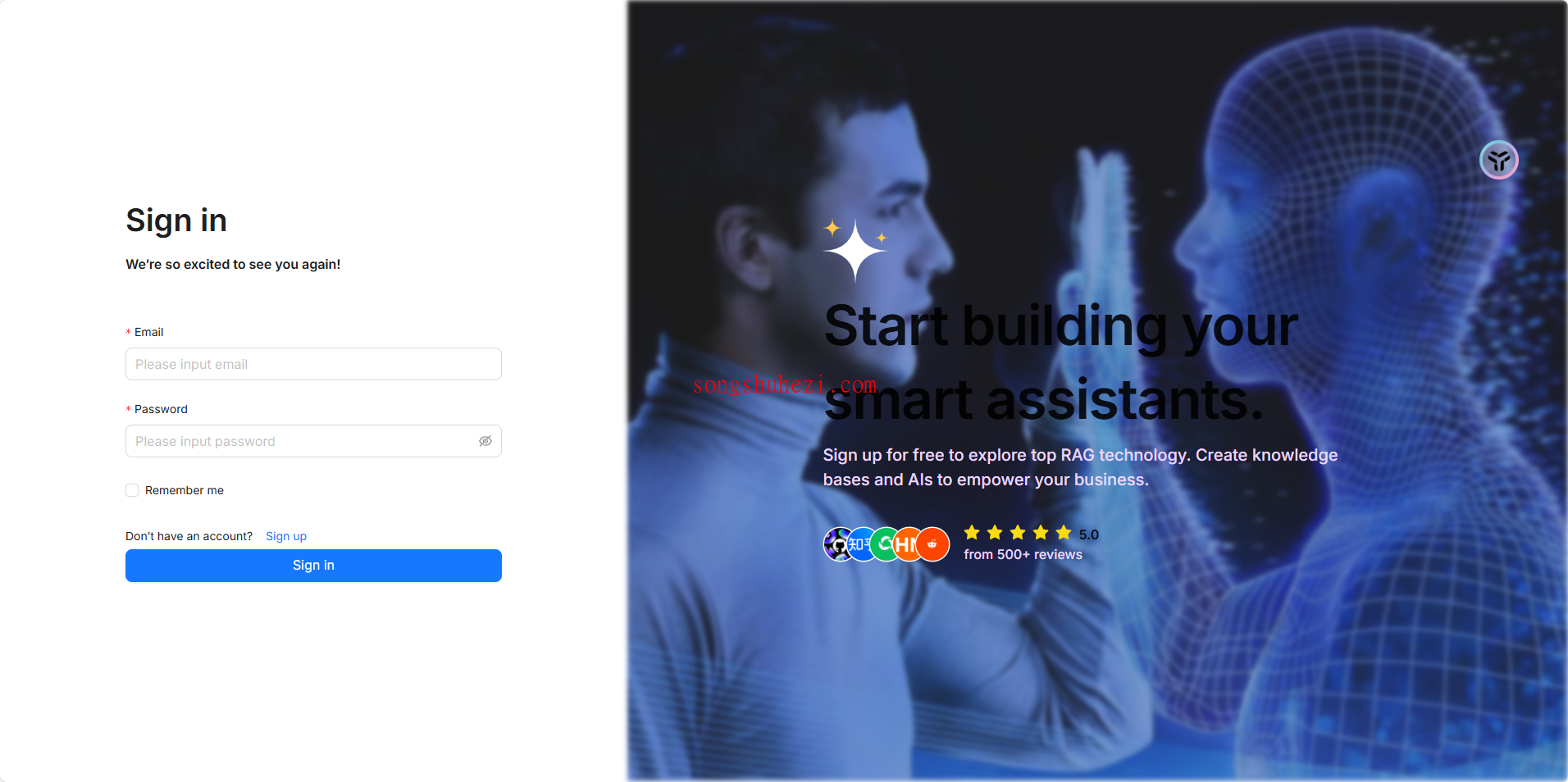
在登录页面,你可以随便输入一个符合邮箱格式的账号注册,比如 example@demo.com。注意哦,第一个注册的账号默认是管理员账号,所以一定要记得保存好你的邮箱信息。
注册完成后,点击登录,就可以直接进入Ragflow的主界面了。放心,所有数据都保存在本地,不用担心泄露。
3、使用Ragflow
1.获取api-key
现在,我们需要获取一个API密钥。这个密钥是连接DeepSeek模型的关键。
由于官网服务器资源紧张,已暂停 API 服务充值,所以我们需要其他的方法来获取,具体请看这篇:【获取DeepSeek API】
2.配置本地知识库
有了 API-Key 后,就可以正式开始配置啦。接下来,我们需要上传资料来创建一个本地知识库。DeepSeek 支持多种格式的文档上传,这点真的很贴心。无论是普通的 PDF 文件,还是扫描版的 PDF 文档,它都能轻松搞定。这样一来,即使是一些老旧的扫描件资料,也能被纳入知识库中,实用性非常高。
上传文件的操作也很简单,直接把文件拖进去就行了。上传之后呢,需要稍微等一会儿,等系统完成文档解析。解析的速度取决于文件的大小和复杂程度,不过效果还是很不错的。从解析结果来看,DeepSeek 的文档处理能力确实挺强,文字识别清晰准确,基本不用担心丢失重要信息。
3.创建对话助理
等文档解析完成后,接下来就是创建对话助理了。在这个步骤中,有一个关键设置需要注意:一定要在模型设置里把默认模型替换为 deepseek-chat,这样才能充分发挥 DeepSeek 的对话能力。设置完成后,你的对话助理就可以正式上线了!
这个对话助理可以用来干嘛呢?简单来说,它可以根据你上传的资料,回答各种相关问题。比如说,你上传了一份产品说明书,那么你可以直接问它产品的具体参数或者使用方法,它会根据知识库里的内容给出答案。这个功能简直是效率提升神器,特别适合需要快速查找信息的场景。
相关资源获取
为了大家方便,本教程所有用到的软件资源我都统一整理到网盘中了,大家需要的自行下载就好。
网盘链接:https://pan.quark.cn/s/4e3a3843a943
如果我不想本地部署,可以吗?
如果你觉得本地部署太麻烦,也可以选择使用在线的DeepSeek模型。在线模型的确方便,但也有一些缺点,最明显的就是隐私问题。毕竟你得将所有的数据上传到服务器。如果这些数据特别敏感,可能会让你不太放心。
另外,很多在线服务都提供免费额度,但一旦超过免费额度,后续就得收费了。长期使用下来,成本可能会逐渐增加。因此,如果你对隐私有较高的要求,或者需要处理大量文件,本地部署仍然是更理想的选择。
最后
说实话,虽然本地部署的过程有点繁琐,但一旦搭建完成,你就可以拥有一个完全属于自己的知识库,而且数据隐私得到保障,处理文件的速度和容量都不受限制。对于程序员来说,这样的搭建方式既能满足需求,又能提升工作效率。希望大家在搭建过程中能够有所收获,不管是对隐私的重视,还是对高效知识库管理的追求。
其实,真正的好处不仅仅在于隐私保护,更在于你可以根据自己的需求定制个性化的知识库,随时随地获得你所需要的信息。所以,哪怕有点复杂,还是值得一试的!

反爬虫抓取,人机验证,请输入验证码查看内容
请关注本站公众号回复关键字:“2024”,获取验证码。
打开微信扫描上方二维码关注微信公众号



 RSS
RSS