






DeepSeek R1的原理
大家还记得ChatGPT 3.5和4.0刚上线时的震撼吗?它们在自然语言处理上的表现可以说是质的飞跃,但也有不少学术大佬吐槽,说Transformer架构本质上只是个统计模型,缺乏真正的逻辑推理能力。比如,经典的“3.11和3.8哪个大”问题就暴露了这一点。
为了弥补这些不足,OpenAI推出了ChatGPT-o1模型,通过强化学习(RL)模拟人类思维,在逻辑推理领域取得了显著提升。而DeepSeek同样也不甘示弱,采用了独特的强化学习策略,推出了R1版本,其性能甚至在某些方面超越了OpenAI的模型。
那么,DeepSeek R1是如何做到的呢?今天就来一起深挖它的核心原理。
强化学习的常见算法回顾
在进入DeepSeek R1的具体实现之前,我们先来简单回顾一下强化学习中常见的几种算法,看看DeepSeek为何没有选择它们,而是另辟蹊径。
1. DPO(Direct Preference Optimization)
DPO的核心思想是让模型的输出尽可能接近人类偏好的答案,同时避免模型偏离基础模型(base model)。其训练过程需要标注数据,格式为 {prompt; chosen; reject},即每个输入需要有一个“优选答案”和一个“拒绝答案”。通过优化如下公式,模型会倾向于生成更符合人类偏好的答案:
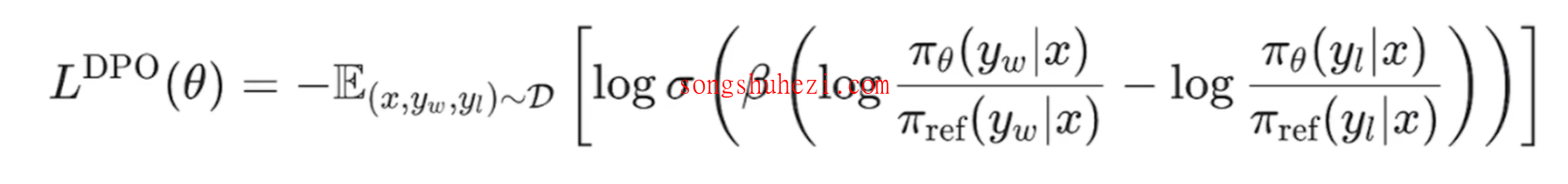
不过,DPO也有明显的缺陷:
- 标注成本高:人工标注成对数据耗时耗力,且难以泛化。
- 正则项影响:正则项(pai_ref)设置过大可能导致模型过于简单,难以捕捉复杂模式。
- 推理过程僵化:如果训练数据的推理过程较长,DPO可能让模型“死记硬背”,失去灵活性。
2. PPO(Proximal Policy Optimization)
PPO是强化学习中的经典算法,它通过限制策略更新的幅度,保证模型训练的稳定性,同时利用优势函数(advantage function)对动作的相对好坏进行评估。其核心思想类似于教练指导球员踢球,既不能让动作变化过大,也不能完全不变。
PPO的架构如下:
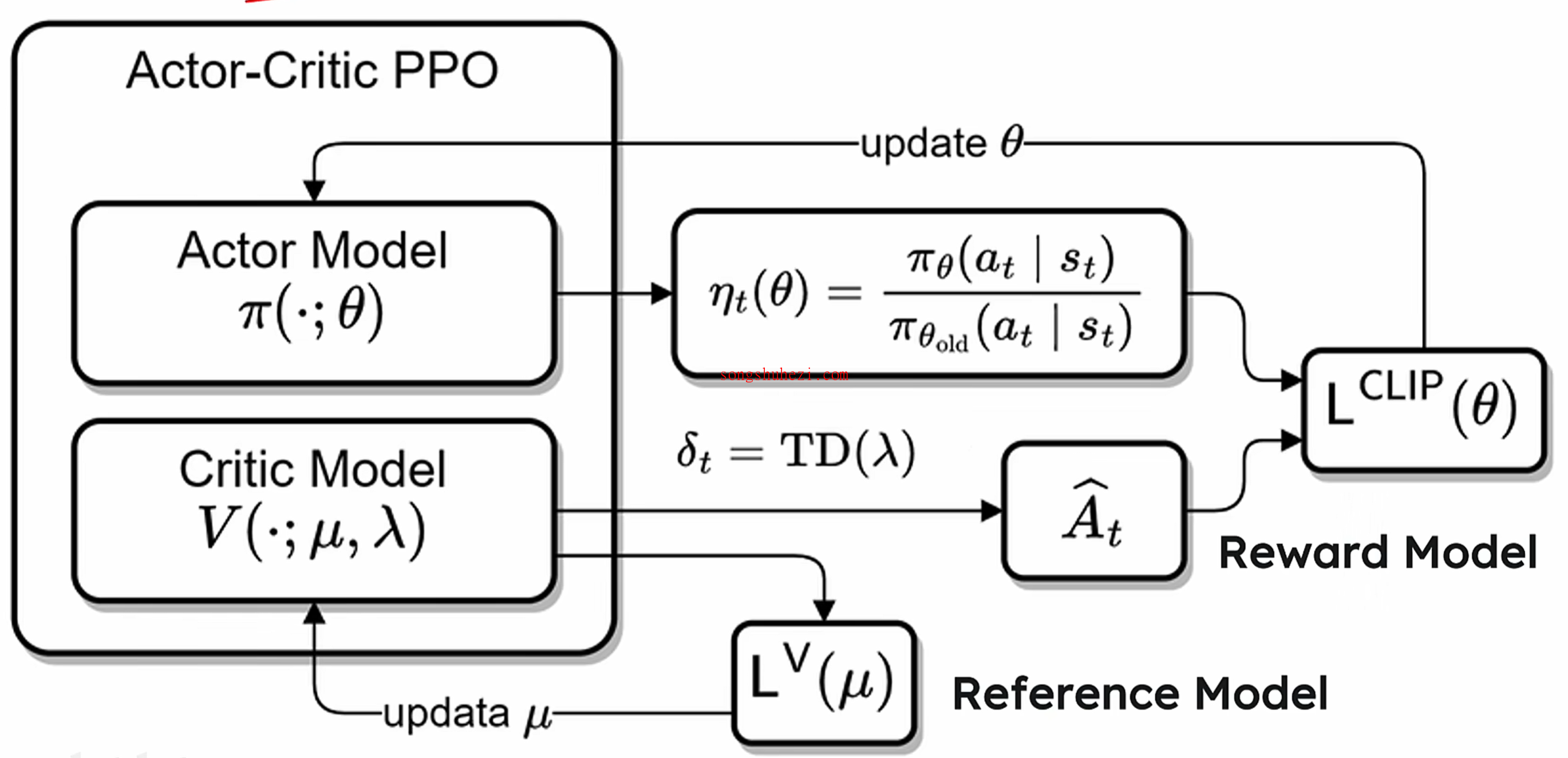
其优化公式为:

虽然PPO在很多场景下表现良好,但它也有一些不足:
- 依赖Critic模型:Critic模型需要准确估计状态的价值,而这往往非常复杂且难以泛化。
- 算力需求高:PPO需要同时训练Policy模型和Critic模型,对算力和显存的要求较高。
- 稀疏奖励问题:PPO的奖励分配通常是基于整个响应,而不是逐个token,这可能导致奖励信号过于稀疏。
DeepSeek R1的创新算法
针对上述算法的缺陷,DeepSeek采用了一种全新的强化学习方法,称为 Group Relative Policy Optimization(GRPO)。与PPO相比,GRPO在架构和优化策略上都有显著不同。
GRPO的核心架构
以下是GRPO与PPO的架构对比:
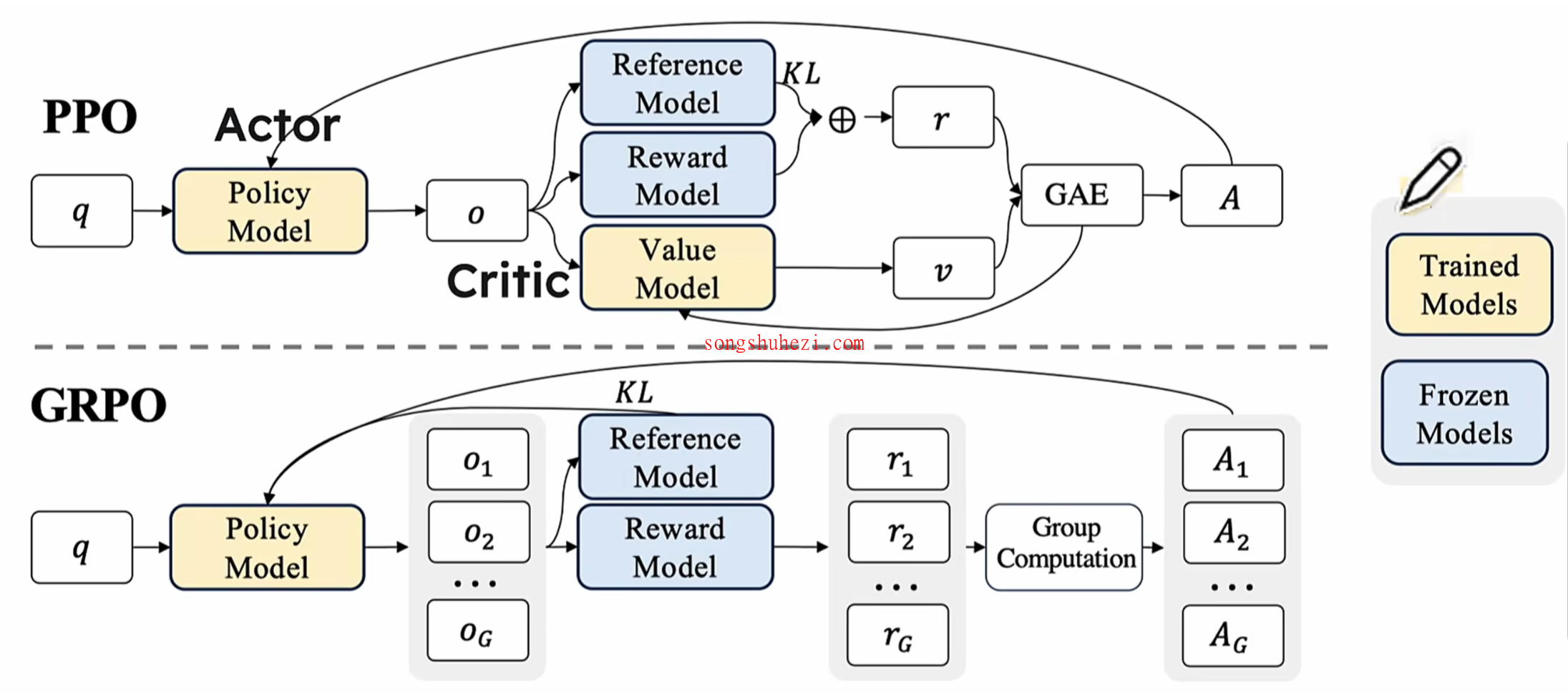
可以看到,GRPO有以下几个关键变化:
- 多响应生成:对于同一个prompt,GRPO会生成多个response,并对它们进行比较。
- 去掉Value模型:GRPO不再依赖Critic模型,而是通过组内计算的优势值(Advantage)来评估动作的好坏。
- 组内奖励计算:多个响应的奖励经过组内计算,生成对应的优势值。
GRPO的优势
- 减少不确定性:去掉Value模型后,避免了因Critic模型预测不准而导致的误差。
- 简化计算:通过组内的Advantage计算公式,直接评估当前动作的相对好坏,无需复杂的Value模型。
- 强化奖励信号:GRPO通过对比多个响应的reward,能够更准确地引导模型优化方向。
GRPO的关键公式解析
1. Advantage计算公式
GRPO中,Advantage值的计算公式如下:
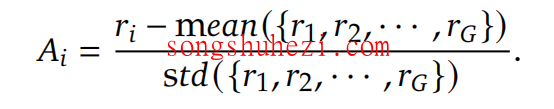
- oi:表示某个动作的得分。
- mean:表示所有动作得分的平均值。
- 若 oi > mean,说明该动作优于平均水平,模型需要向该动作靠拢。
2. Reward函数
GRPO的Reward函数如下:

与PPO不同,GRPO将KL散度直接加入Reward函数,而不是作为惩罚项。这种设计避免了复杂的Advantage计算,同时通过控制策略变化的速度,提升了训练的稳定性。
3. Importance Sampling
GRPO的Loss函数核心部分如下:
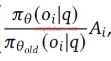
- 分子:表示新模型输出某个动作的概率。
- 分母:表示旧模型输出该动作的概率。
- 比值:若比值大于1,说明新模型更倾向于该动作,从而强化该动作的优势。
R1的训练流程与性能表现
DeepSeek R1的训练流程分为两个阶段:
- R1-Zero:直接在基础模型上进行强化学习,只提供答案,不提供推理过程。
- R1:在R1-Zero的基础上,利用大量的长链式推理(Long-CoT)数据进行微调。
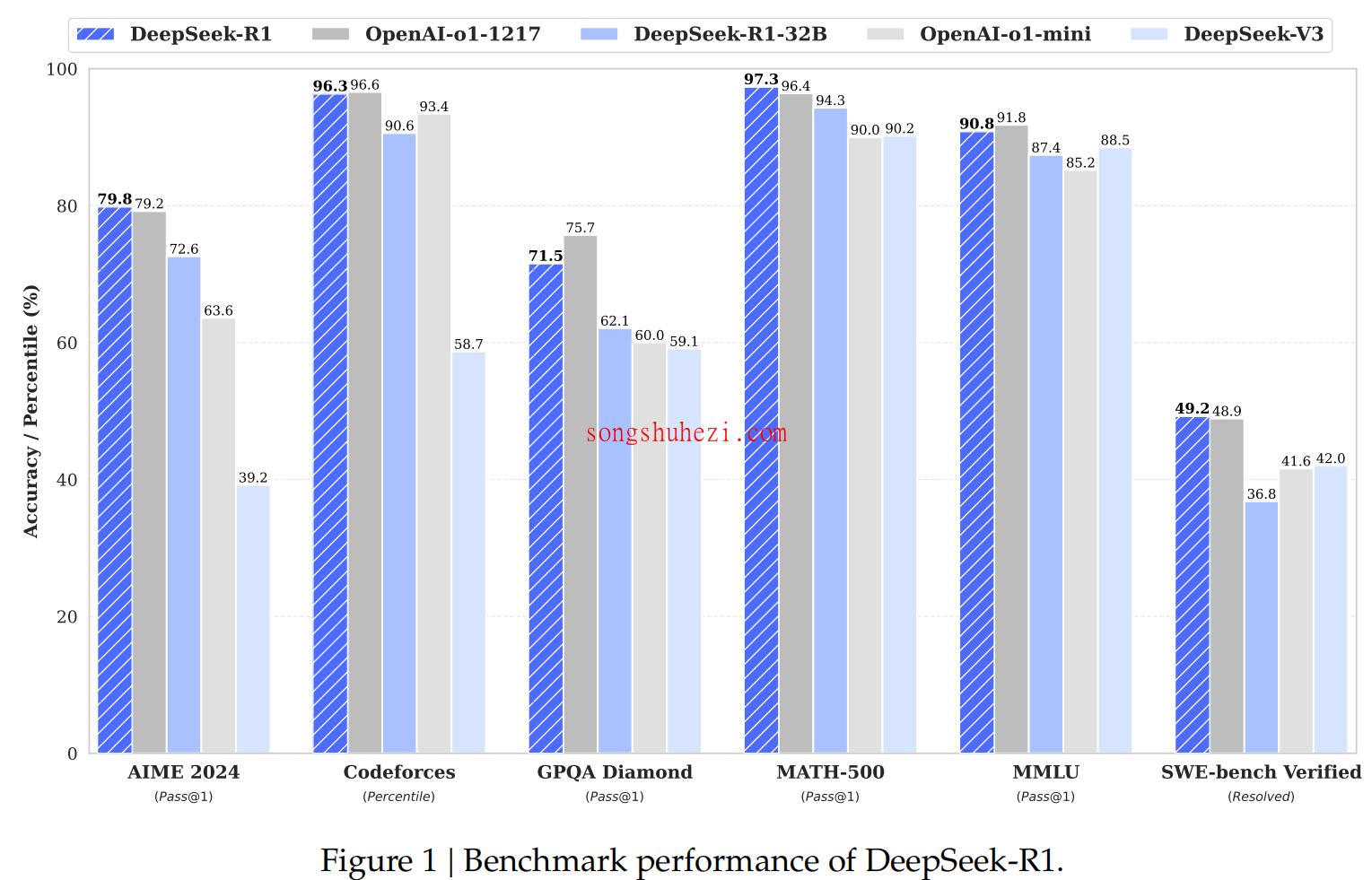
以下是R1与其他模型的性能对比:
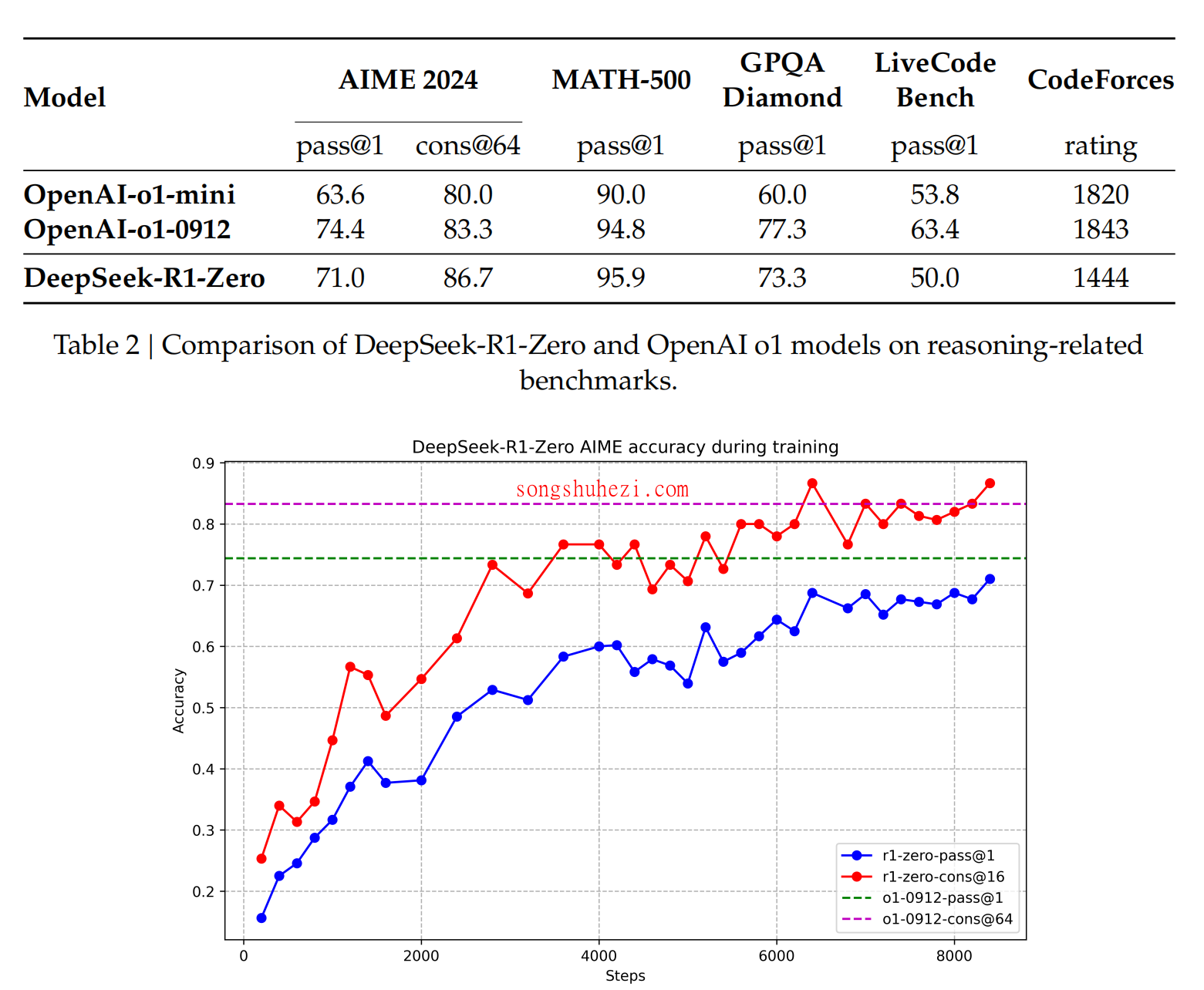
可以看到,R1在逻辑推理、数学和编程等领域表现尤为突出。
结语
DeepSeek R1的创新之处在于它大胆地简化了强化学习的流程,同时通过精妙的奖励设计和优化策略,显著提升了模型的逻辑推理能力。在我看来,R1的最大亮点是其“aha moment”,即模型在训练过程中展现出的自我反思能力。如果未来这一能力能够进一步发展,或许我们就能真正迈向AGI的时代了。

反爬虫抓取,人机验证,请输入验证码查看内容
请关注本站公众号回复关键字:“2024”,获取验证码。
打开微信扫描上方二维码关注微信公众号



 RSS
RSS