






循环采集多个网页详情数据:批量抓取多个网址的详情页信息
在处理多个网址时,你是否希望能自动打开每个网址,提取其详情页中的内容,比如京东商品详情、招聘网站的职位信息,或者是抖音视频的详细信息?手动处理不仅繁琐,效率低下。今天就为大家介绍一款应用,它能够自动循环打开多个网址,批量采集网页数据,节省时间和精力。
应用场景
这款应用特别适合于需要逐个访问不同详情页网址并提取数据的场景,比如:
京东商品详情页:采集商品名称、价格、评论等详细信息。
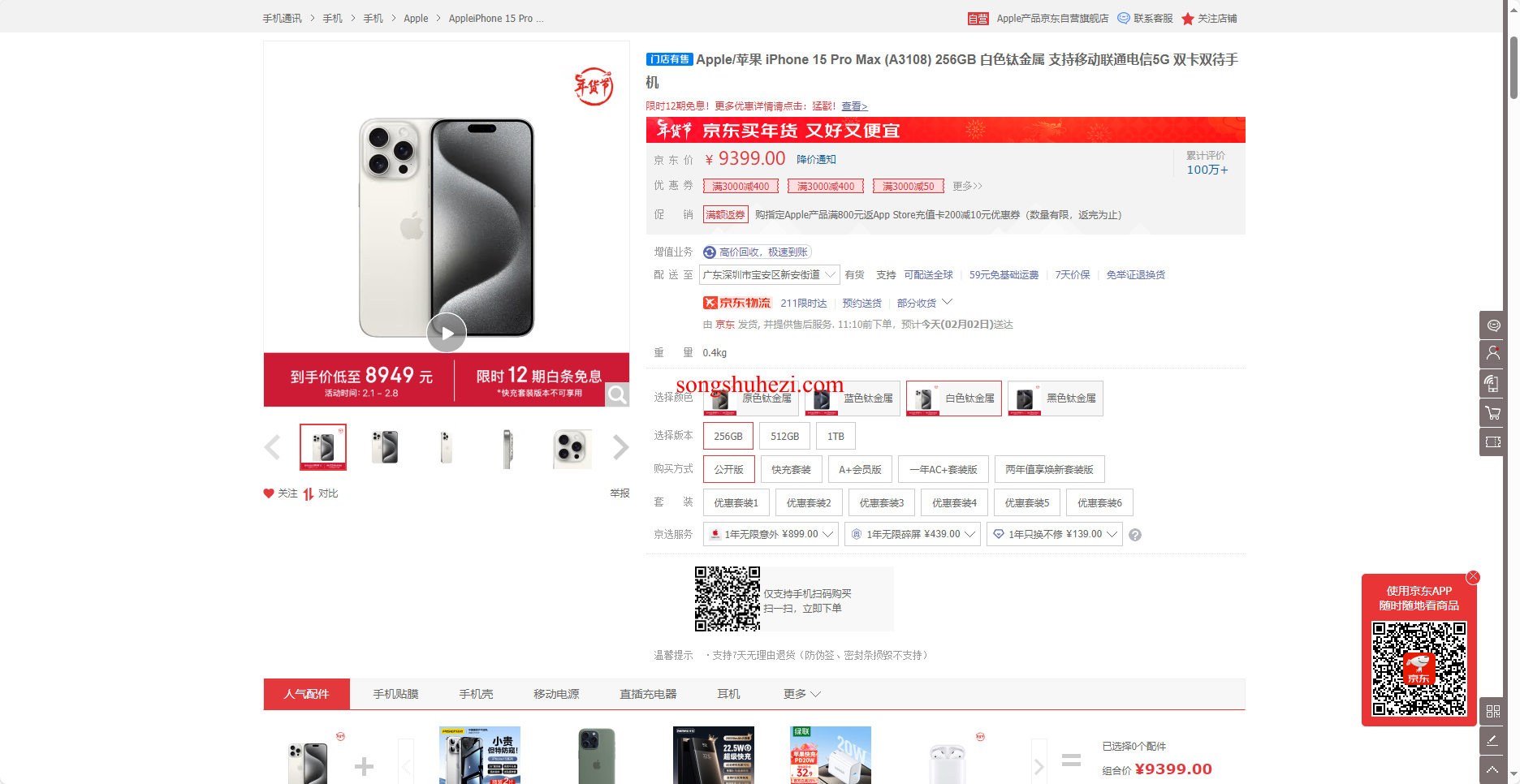
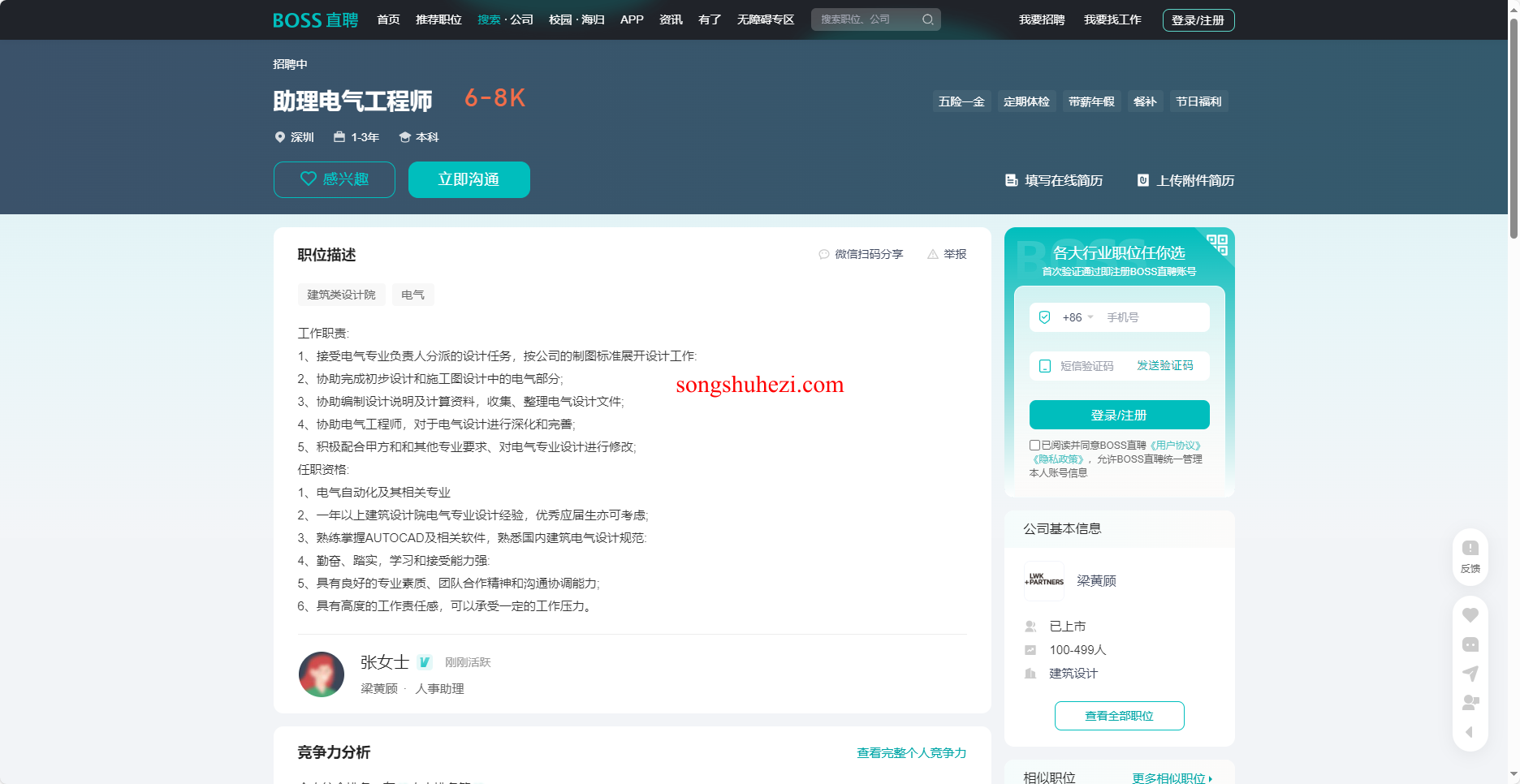
招聘网站详情页:提取职位名称、公司信息、工作地点等内容。
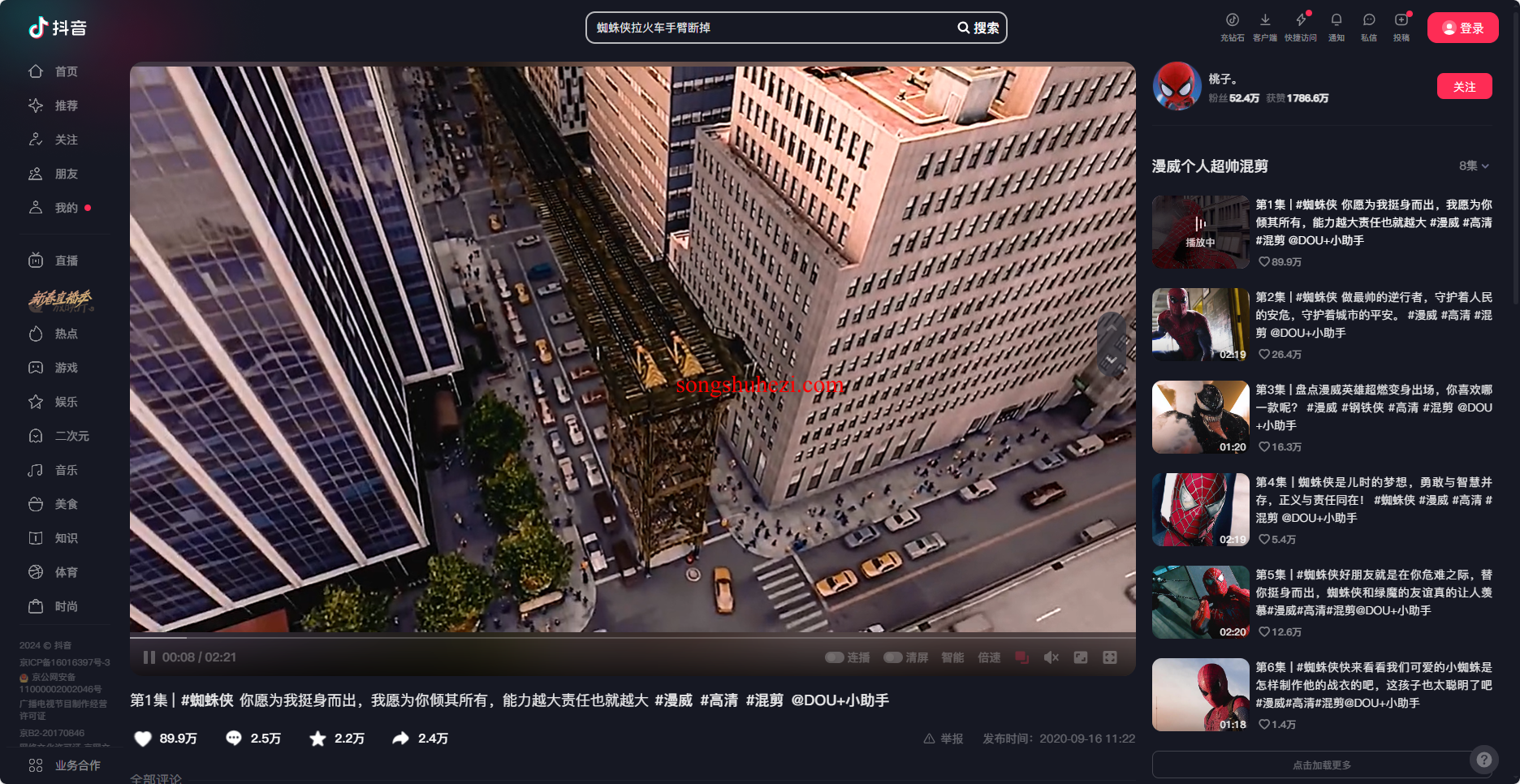
抖音视频详情页:抓取视频标题、发布时间、点赞数等数据。
应用讲解
1. 准备工作
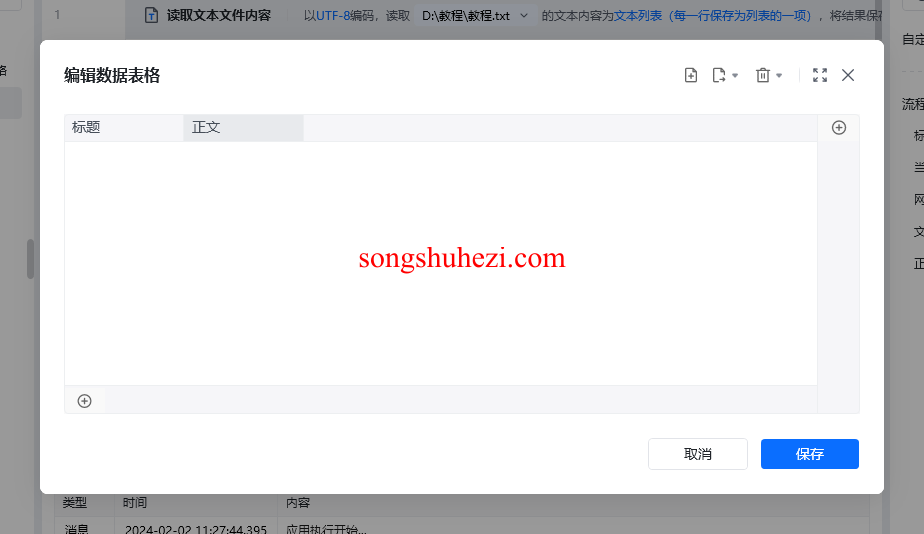
首先,你需要准备好一个数据表格来存储采集到的详情页数据,例如:网页标题、正文内容等。此外,还需要一个txt文件,该文件内包含所有待采集的网页链接,每个链接占一行。
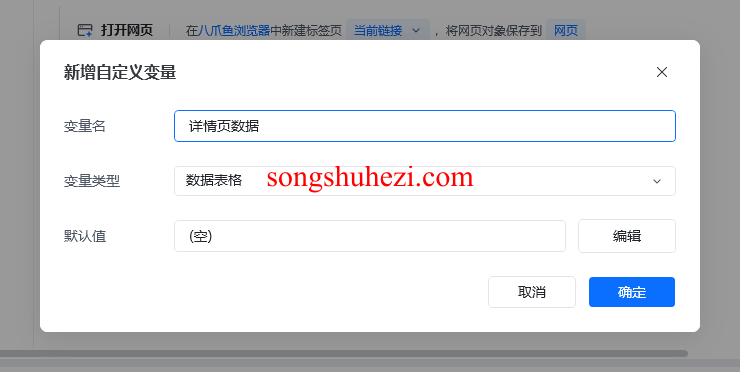
2. 读取txt文件中的网址
在应用中,我们首先使用**“读取文本文件内容”指令**来读取txt文件中的网址列表。操作步骤如下:
选择文件路径:找到你准备好的txt文件,选择路径。
存储为文本列表:将读取的内容存储为一个列表,每个网址作为列表中的一项,供后续循环使用。
3. 循环打开多个网址
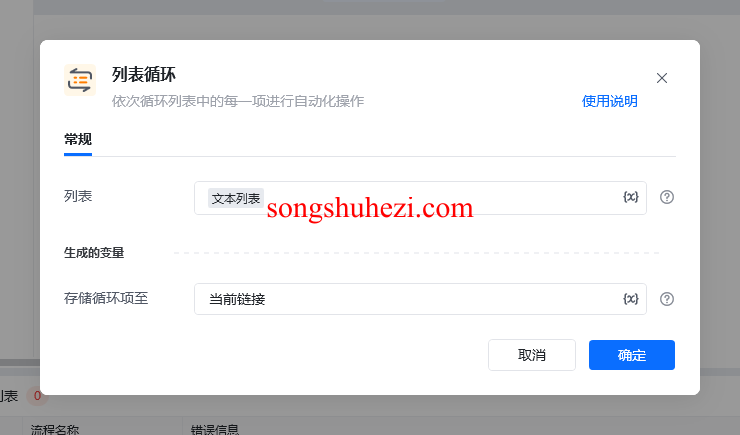
接下来我们需要创建一个列表循环,以便逐个打开网址并采集数据。操作步骤如下:
列表循环:通过RPA工具创建一个循环,选择刚刚读取的文本列表作为循环对象,并为每个循环项命名,比如“当前链接”。
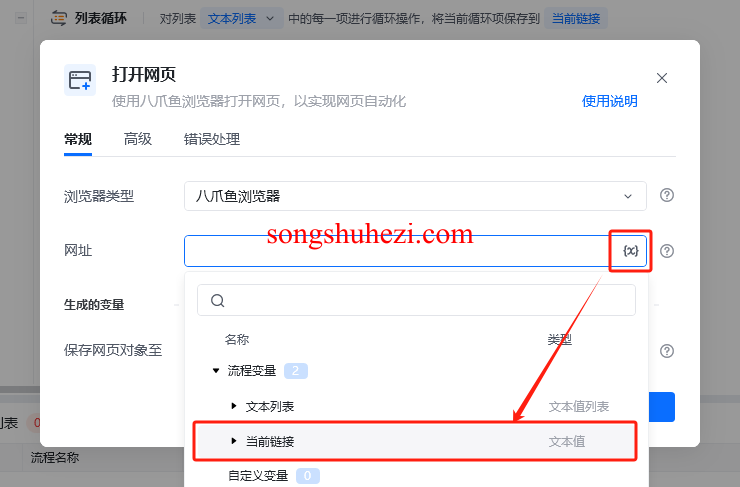
打开网页:在每次循环时,使用“打开网页”指令,网址选择当前循环的链接。这样每次循环都会自动打开txt文件中的不同网址。
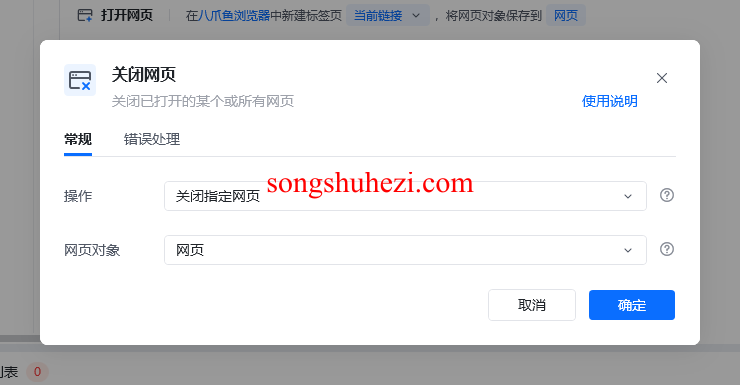
关闭网页:为了避免网页过多导致卡顿,每次采集完数据后,别忘了在循环内加入“关闭网页”指令。
4. 采集网页数据
在每个网页打开后,我们需要采集具体的数据,如网页的标题、正文等。为了让流程更简洁,我们可以将采集步骤封装到一个子流程中。操作步骤如下:
创建子流程:在循环打开网页后,创建一个子流程,专门用于采集每个网页的具体数据。
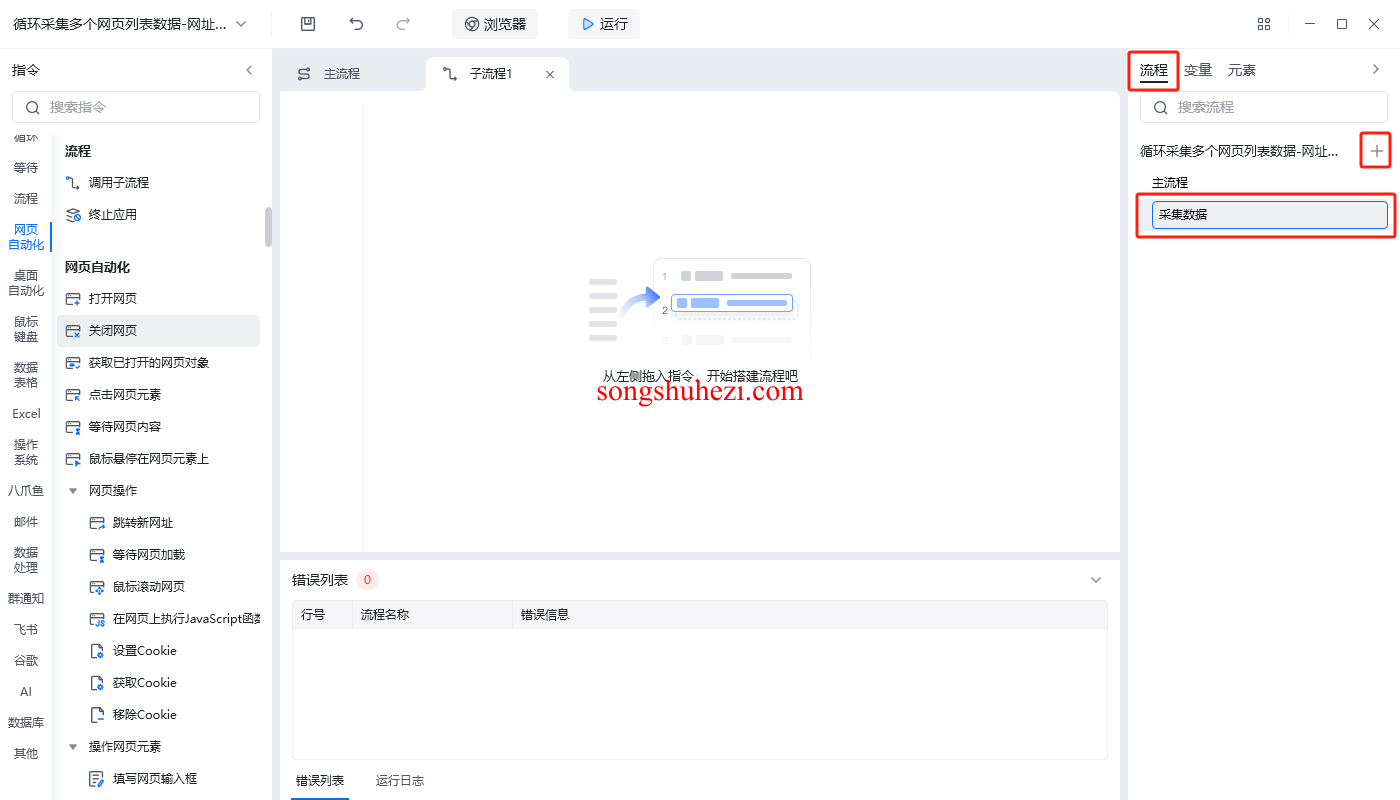
采集网页元素信息:使用“获取网页元素信息”指令,捕获网页中的标题、正文等内容。

写入数据表格:将采集到的数据写入到准备好的数据表格中,每个网页的标题和正文占据一行,列与数据相对应。
5. 写入数据表格
在子流程中完成数据采集后,将数据按行写入数据表格。具体操作如下:
写入标题和正文:将采集到的标题、正文分别写入数据表格的不同列。
检查数据格式:确保每次写入的数据格式一致,以便后续导出。
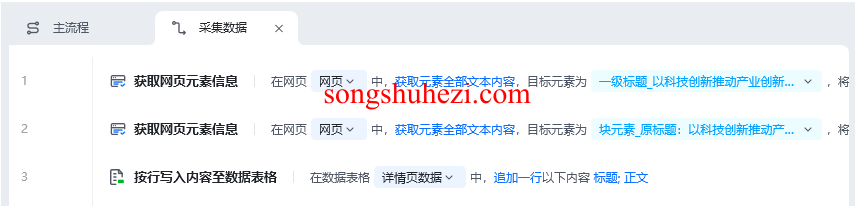
6. 导出数据表格
所有网页的数据采集完毕后,我们需要导出数据表格。别忘了勾选**“带表头导出”**,这样在导出时,数据表头(如标题、正文)会被自动包含。
7. 运行应用
当所有步骤完成后,运行整个应用。程序会自动依次打开txt文件中的每个网址,采集网页数据,并将结果写入表格,最后导出为一个带有所有采集数据的表格文件。

应用搭建的具体步骤
- 准备txt文件和数据表格:创建包含多个网址的txt文件,并准备一个空白数据表格,设置好表头(如标题、正文等)。
- 读取txt文件:使用RPA工具读取txt文件中的网址列表,将其存储为文本列表。
- 列表循环:创建一个列表循环,每次循环打开一个网址,采集数据并关闭网页。
- 创建子流程:将采集网页标题和正文的操作封装到一个子流程中,便于管理。
- 采集网页数据:通过“获取网页元素信息”指令,逐个采集每个网页的标题、正文等数据。
- 写入数据表格:将采集到的数据按行写入数据表格中,每个网页对应一行数据。
- 导出数据表格:所有采集任务完成后,将表格导出,保存为本地文件。
我的使用感受
通过这个应用,循环采集多个详情页数据变得非常轻松,尤其是在处理大量网页时,它的自动化优势尤为突出。以前我需要逐个打开网址并手动复制数据,现在只需要准备好网址列表,程序就能自动完成所有任务。无论是京东商品、招聘网站的职位信息,还是抖音视频的详细数据,这个应用都能快速抓取并导出。
如果你需要批量采集多个网址的详情页信息,这款应用绝对能帮你大大提升工作效率!


反爬虫抓取,人机验证,请输入验证码查看内容
请关注本站公众号回复关键字:“2024”,获取验证码。
微信搜索公众号:“RPA编程教程”或者“rpa1499” 或微信扫描上方二维码关注微信公众号



 RSS
RSS