






八爪鱼RPA教程
开始监听网页请求:如何监听并获取网页请求响应信息
八爪鱼RPA【支持公众号/小红书/抖音/淘宝抓取数据】=>点击查看
在一些网页数据抓取任务中,网页源码中可能不会显示我们所需的数据。此时,通过监听网页请求可以获取网页后台接口返回的数据,尤其是像图表数据、动态加载数据等。这篇文章将详细介绍如何使用【开始监听网页请求】指令,抓取这些隐藏的数据。
1. 网页对象的选择
首先,你需要选择一个目标网页对象。这个网页对象可以是通过【打开网页】或【获取已打开的网页对象】指令创建的,确保系统能够在该网页中开始监听请求。比如,你可以打开一个数据页面,如:https://q.10jqka.com.cn/#refCountId=www_50a1b74a_693。
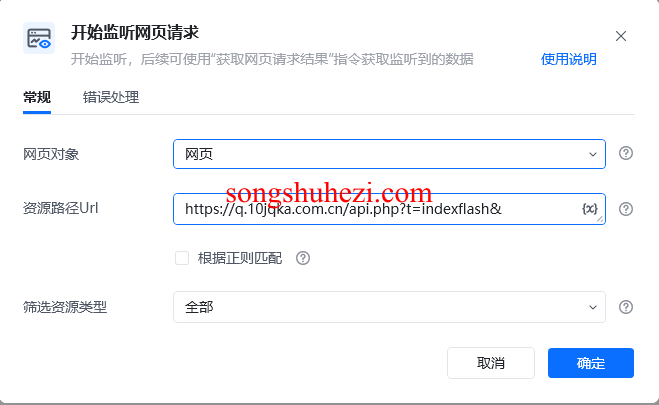
2. 获取资源路径Url
资源路径Url 是你要监听的网页请求的路径。获取这个Url需要你手动在浏览器的开发者工具中进行操作。以下是详细步骤:
- 打开开发者工具:在谷歌浏览器中打开你需要抓取数据的网页,按
F12键进入开发者工具,然后点击 Network 选项卡。 - 重新加载网页:按
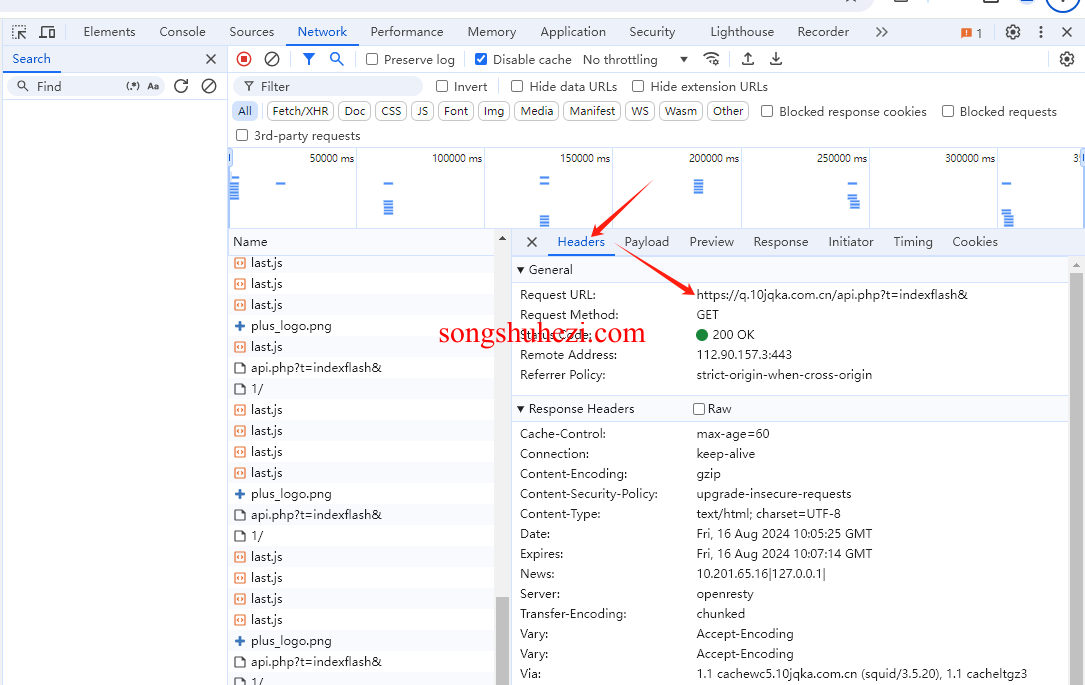
Ctrl+R重新加载网页,这时浏览器会显示该页面发送的所有网络请求。 - 找到目标请求:在 Network 面板中,逐个查看每个请求的 Preview,找到包含你需要数据的接口。如果找到合适的接口,请记下它的 Headers 中的请求Url。
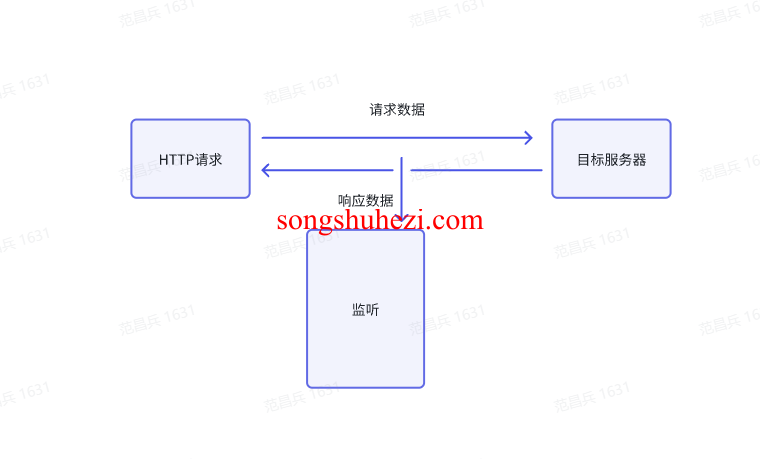
例如,你想获取某个图表的后台数据,浏览器源码中没有显示相关数据,但你可以在 Network 中找到相应的请求接口,并获取数据。
3. 监听网页请求指令的设置
接下来,在【开始监听网页请求】指令中进行相关设置:
- 网页对象:选择已经打开的网页对象。
- 资源路径Url:输入你从浏览器开发者工具中获取到的资源路径Url,例如
https://q.10jqka.com.cn/api.php?t=indexflash&。
当配置完成后,系统会监听你指定的Url,捕获所有相关的请求和响应信息。
4. 请求响应信息
监听开始后,你可以获取以下重要的网页请求信息:
- 请求Url:记录你监听的资源路径。
- 请求类型:如GET或POST等请求类型。
- 状态代码:返回的HTTP状态码,如200(成功),404(未找到),500(服务器错误)等。
- 请求标头(Headers):请求时携带的标头信息。
- 响应内容(Preview/Response):该请求返回的响应数据,这是获取隐藏数据的关键部分。
这些信息能够帮助你获取到网页源码中没有直接显示的内容,尤其是通过接口返回的数据。
5. 使用示例
以监听某个股票行情网站的请求为例:
- 打开网页:使用【打开网页】指令打开网址 https://q.10jqka.com.cn/#refCountId=www_50a1b74a_693。
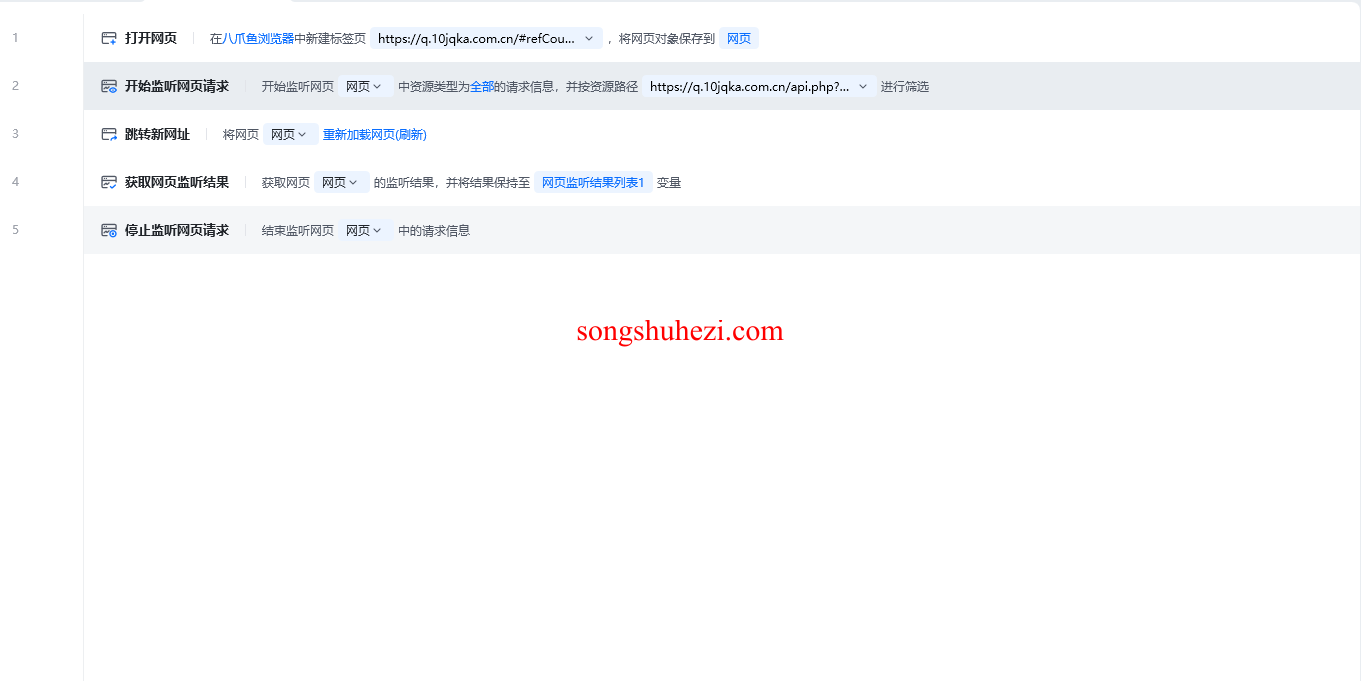
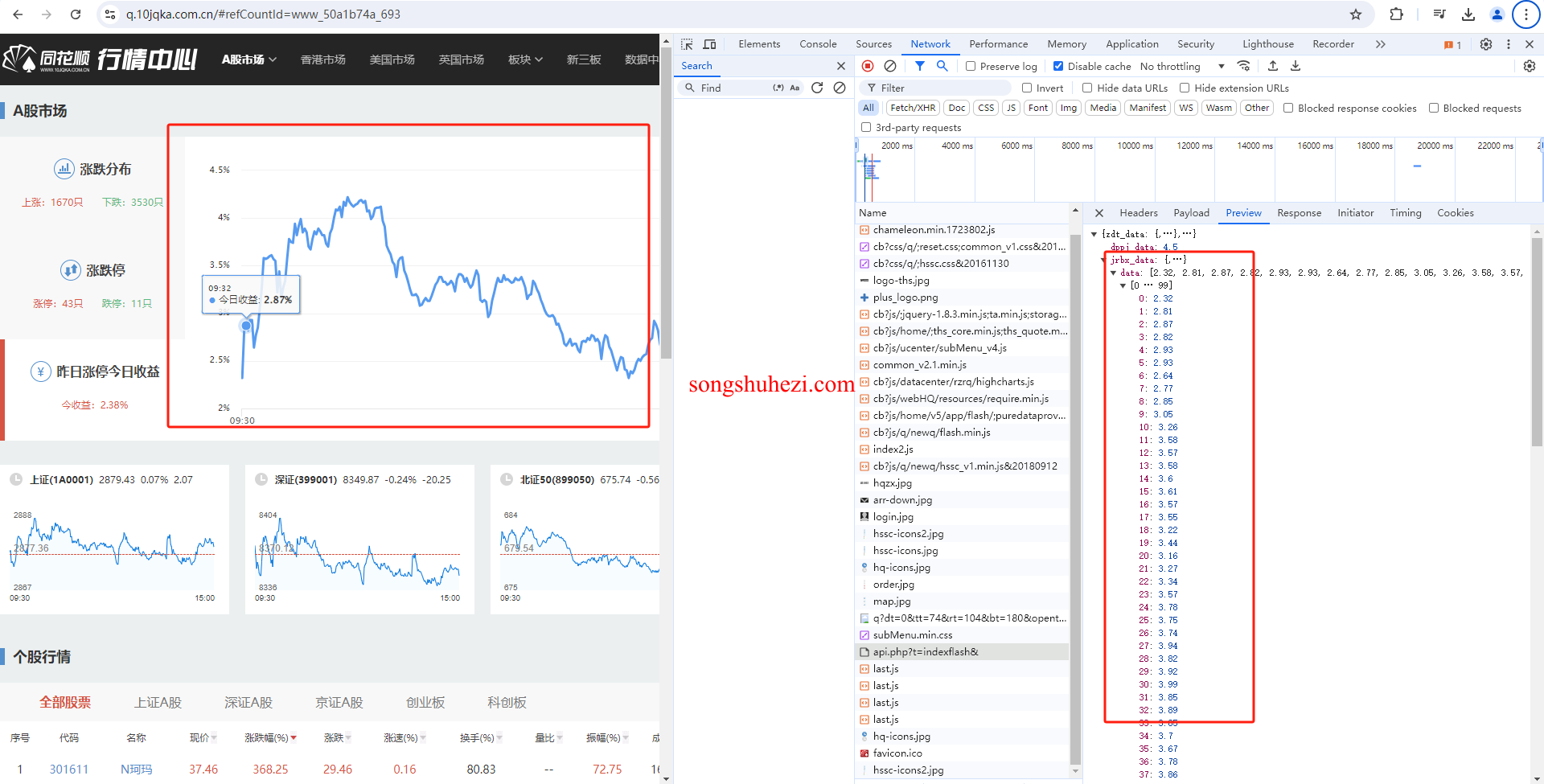
- 获取资源路径:通过谷歌浏览器的开发者工具,在 Network 面板中找到
https://q.10jqka.com.cn/api.php?t=indexflash&这个接口,它返回了股票数据的相关信息。
- 开始监听请求:使用【开始监听网页请求】指令,输入获取到的资源路径Url,并开始捕获返回的数据。
我的感受
在我看来,监听网页请求是数据抓取中的一项强大功能,尤其是在需要获取页面不直接显示的接口数据时,这个工具能快速准确地找到我们需要的信息。感觉嘛,虽然手动操作开发者工具略显繁琐,但通过获取资源路径Url,再结合【监听网页请求】指令,能让数据采集变得轻松、精准。
想深入了解DeepSeek的核心玩法 扫描下方二维码加入微信群 
阅读全文
×
初次访问:反爬虫,人机识别
反爬虫抓取,人机验证,请输入验证码查看内容
请关注本站公众号回复关键字:“2024”,获取验证码。
微信搜索公众号:“RPA编程教程”或者“rpa1499” 或微信扫描上方二维码关注微信公众号



 RSS
RSS