






循环采集瀑布流网页列表数据:轻松抓取微博、小红书等滚动加载内容
你有没有遇到过这种情况:当你想要从微博、小红书等瀑布流式网页采集数据时,随着页面滚动不断加载新的内容,手动采集变得非常繁琐?别担心,今天要给大家介绍一款能帮助你自动采集这些滚动加载数据的工具。
应用场景
这种采集技术特别适合于滚动加载的瀑布流网页。所谓“瀑布流”,指的是当你滚动页面时,新内容会不断加载出来。典型的应用场景包括:
微博:采集微博的动态列表,如用户名、发布时间、内容等信息。
小红书:采集文章、笔记的标题、发布者、时间等数据。
应用讲解
1. 准备工作
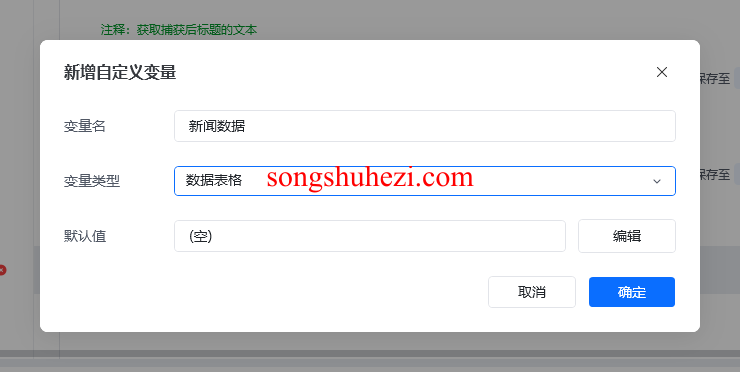
首先,我们需要准备一个表格来存放采集到的数据,设置好表头,比如:标题、来源、发布时间等,以便于后续将数据一行行写入表格中。
2. 打开目标网页并滚动加载数据
接下来,打开你想要采集数据的目标网页(比如微博的某个话题页面或者小红书的搜索结果页)。因为瀑布流页面是随着滚动加载新内容的,为了确保数据全部加载出来,我们需要设置滚动加载。
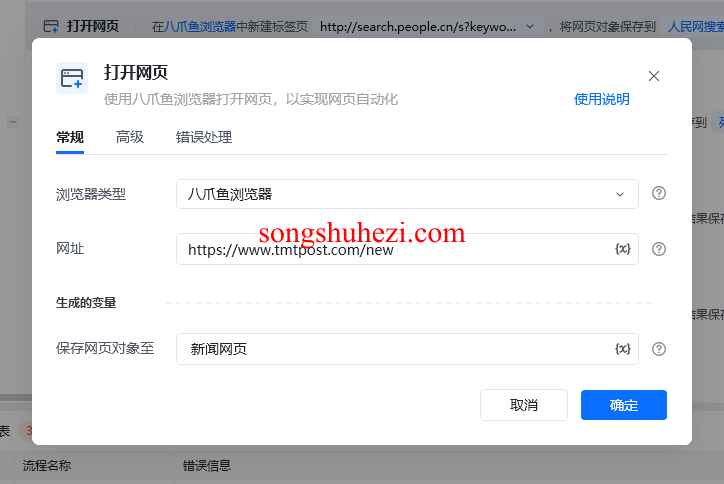
通过RPA工具,可以设置鼠标滚动网页,比如让网页滚动5次,每次滚动加载新数据。为了让数据完全加载出来,每次滚动后我们还需要加一个等待时间,让网页有足够时间加载内容。
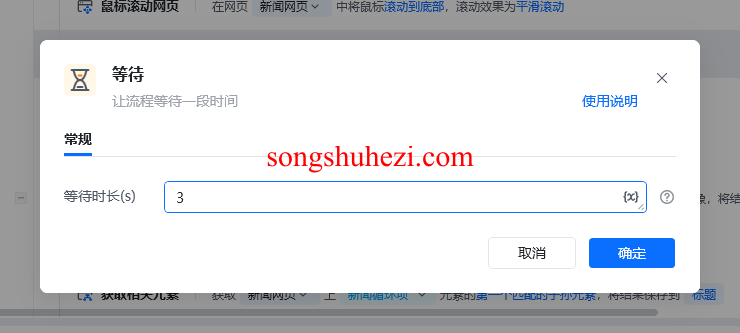
3. 捕获列表项
当网页数据加载完毕后,我们可以开始采集。首先,捕获网页上的列表项,这个列表项需要包含我们想要的所有信息,比如微博的标题、发布时间等。确保每个列表项包含了我们需要的所有元素。
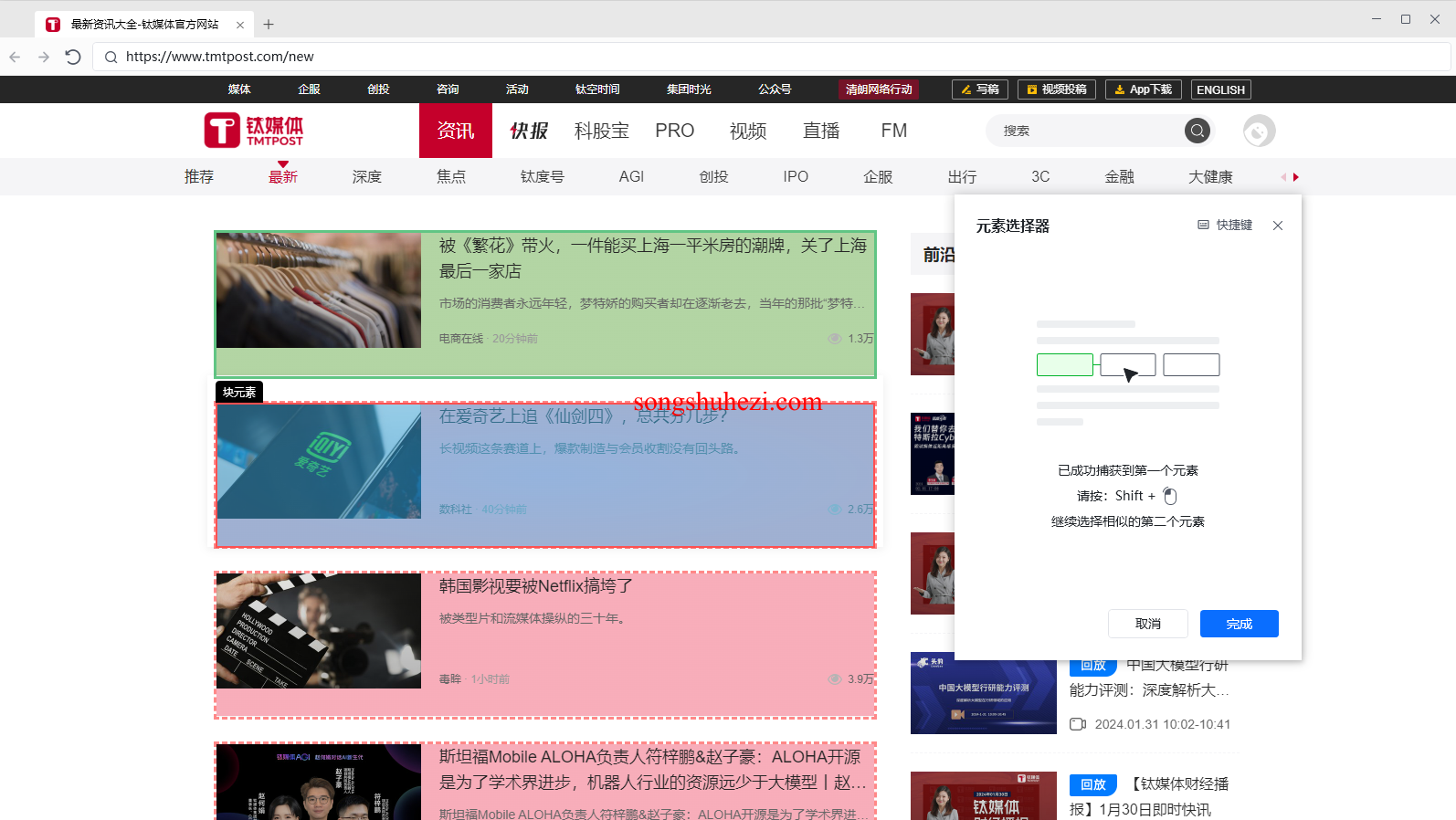
4. 获取相关元素信息
为了能精确采集到列表项中的具体信息,我们需要使用获取相关元素指令。首先,选择捕获到的列表项作为循环项,并为其命名为“新闻循环项”。

接着,我们通过获取相对的xpath路径来指定具体的元素位置,比如文章标题、发布时间等。步骤如下:
选择元素:点击选择元素库的按钮,在下拉菜单中选择【动态元素】文件夹下的新闻循环项。
捕获相关信息:通过+号按钮,捕获我们想要的数据元素,如标题、时间等。
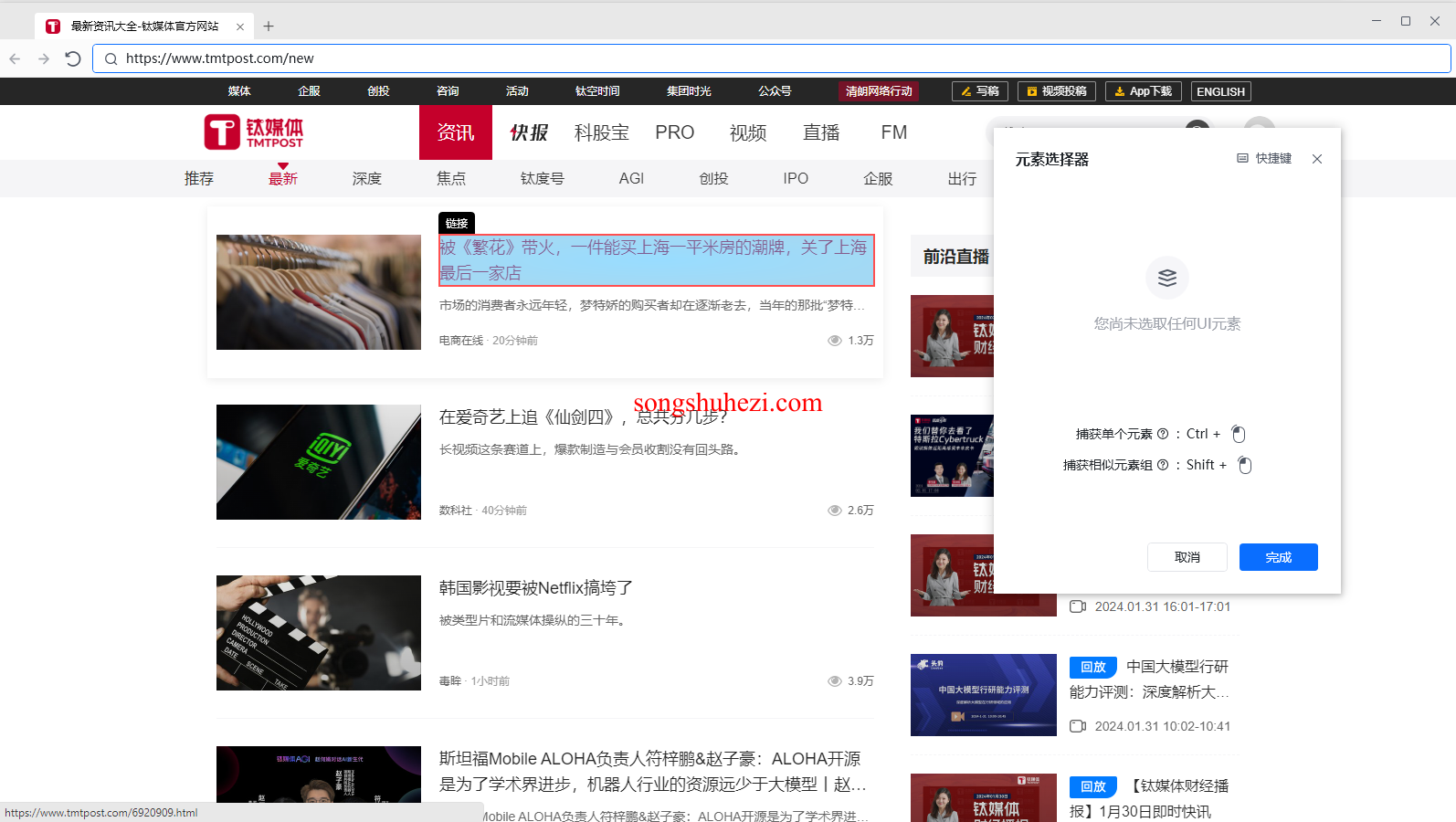
5. 获取元素文本内容
捕获到的网页元素中可能包含多种内容,比如文本、链接等。我们需要明确告诉程序,我们只想获取文本内容,这样才能把具体的数据保存到表格中。
举例来说,我们可以使用“获取网页元素信息”指令,选择元素为我们刚刚捕获的标题元素,然后设置获取元素的全部文本内容。类似的步骤同样适用于获取发布时间等信息。
6. 写入数据表格
当我们成功获取到列表中的数据后,就可以将它们写入之前准备好的数据表格中。我们通过RPA工具将数据按行写入,每个元素对应表格中的一列,比如:
- 第一列写入标题文本。
- 第二列写入发布时间。
7. 导出数据表格
所有的数据写入完毕后,我们就可以将表格导出,保存为本地文件。这样,你就能轻松地得到一份完整的瀑布流网页数据。
应用搭建的具体步骤
打开目标网页:通过RPA工具打开并加载目标页面。
滚动加载数据:设置鼠标滚动次数(如5次),并在每次滚动后设置等待时间,确保新数据加载完毕。
捕获列表项:通过RPA工具捕获包含目标信息的元素框。
循环采集列表项数据:创建一个新闻循环项,使其遍历所有列表项。
获取相关元素信息:通过捕获相对xpath路径,提取列表中的标题、发布时间等信息。
获取文本内容:使用“获取网页元素信息”指令,提取元素中的文本内容。
写入数据表格:将采集到的数据按行写入到我们事先准备好的表格中。
导出表格:将所有数据导出为本地文件。
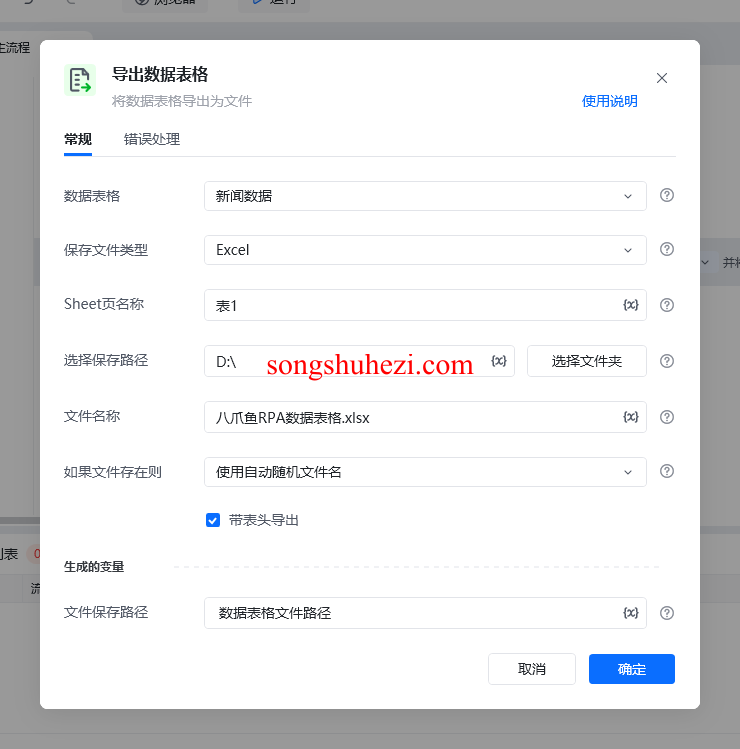
我的使用感受
用这个应用采集瀑布流式网页数据真的非常方便。以前我需要手动滚动页面,一点一点地复制粘贴内容,现在只需要设置好循环滚动和采集项,它就能自动帮我抓取到所有数据。而且,滚动加载后的数据采集也非常准确,不会遗漏任何内容。
如果你经常需要处理微博、小红书等滚动加载的网站数据,这款应用绝对能帮你省下大量时间,快试试看吧!



反爬虫抓取,人机验证,请输入验证码查看内容
请关注本站公众号回复关键字:“2024”,获取验证码。
微信搜索公众号:“RPA编程教程”或者“rpa1499” 或微信扫描上方二维码关注微信公众号



 RSS
RSS