






获取已打开的网页对象:如何在自动化任务中操作已打开的网页
在自动化任务中,通常需要在已打开的网页中进行操作,特别是在某个操作会触发新网页打开时。获取已打开的网页对象指令允许我们根据浏览器类型和匹配方式获取当前打开的网页,并在后续的自动化任务中对这些网页进行操作。该指令对于处理多标签页操作和处理新打开的网页尤其有用。
1. 获取已打开的网页对象的核心组成部分
获取已打开的网页对象指令的核心功能是通过指定的浏览器类型和匹配方式,找到已经打开的网页,并保存该网页对象供后续操作使用。
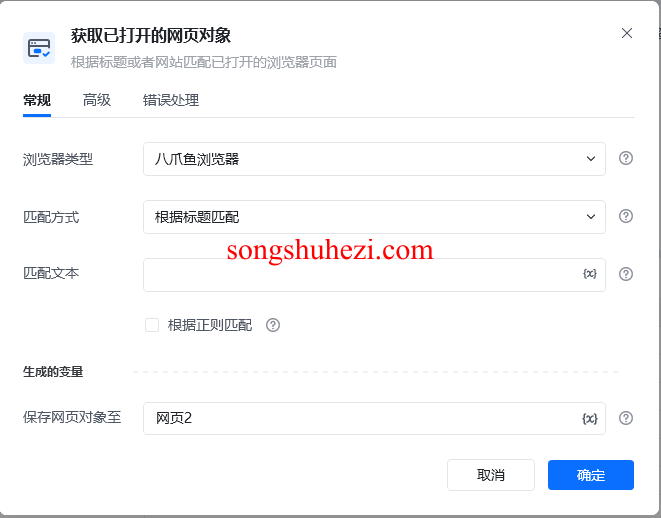
浏览器类型:
- 八爪鱼浏览器:八爪鱼RPA内置浏览器,支持后台运行。
- 谷歌浏览器:需要在本地安装谷歌浏览器,并确保安装了RPA插件。
- Edge浏览器:同样需要本地安装Edge浏览器,并且配置RPA插件。
匹配方式:
- 根据标题匹配:根据网页的标题文字匹配已打开的网页。
- 根据网址匹配:根据网页的URL进行匹配。
- 匹配当前选中的网页:匹配当前正在活动的浏览器标签页。
匹配文本:
- 输入要匹配的网页标题或网址,这将根据之前的匹配方式进行搜索。
保存网页对象至:
将获取到的网页对象保存为变量,供后续指令操作。例如,可以将网页对象保存至变量“网页对象”。
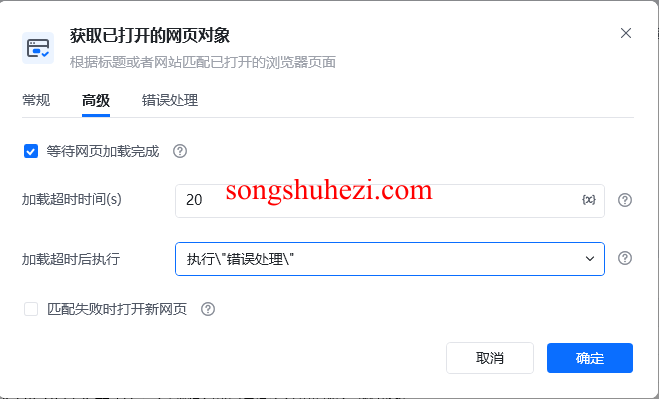
加载超时时间:
- 设置加载超时时间,以秒为单位。超时后执行设定的错误处理机制。
错误处理:
- 在匹配失败或加载超时时,执行设定的错误处理操作,如终止流程或重试该指令。
2. 获取已打开的网页对象使用示例
为了更好地理解获取已打开的网页对象指令的应用,以下通过一个简单的示例来展示如何在任务中获取已打开的网页对象并进行操作。
示例场景:
假设我们在自动化任务中,打开了多个网页,其中需要根据网页标题匹配到百度的页面对象,并获取该页面的链接以供后续使用。
操作步骤如下:
- 使用 获取已打开的网页对象 指令,选择 谷歌浏览器。
- 设置匹配方式为 根据标题匹配,输入“百度”作为匹配文本。
- 将获取的网页对象保存至变量“百度网页”。
- 设置超时时间为 10 秒,确保网页加载完成。
- 使用 打印日志 指令,输出“百度网页”对象的链接信息。
流程图示例:
- 获取已打开的网页对象:使用谷歌浏览器,匹配标题为“百度”的网页,保存对象为“百度网页”。
- 打印日志:输出“百度网页”的链接信息。

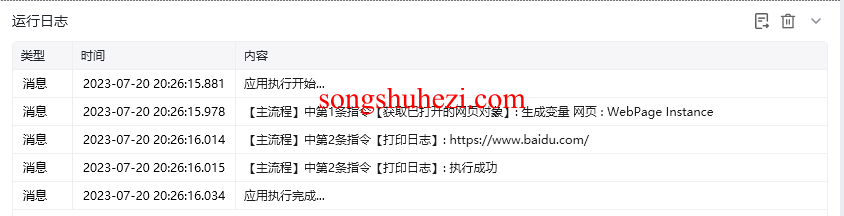
通过这个示例,你可以看到获取已打开的网页对象指令如何帮助我们在已打开的多个网页中灵活操作特定的页面。
3. 获取已打开的网页对象的应用场景
获取已打开的网页对象指令在以下场景中非常有用,尤其适用于多标签页操作、动态网页操作和新页面的处理:
- 处理新打开的页面:在执行某个操作后,新页面被打开时,使用该指令获取新页面对象进行后续操作。
- 多标签页操作:在任务中处理多个浏览器标签页时,可以根据标题或网址匹配不同的页面进行相应的操作。
- 动态网页管理:在自动化任务中,需要根据特定条件操作已打开的网页,而不是重新打开新的页面。
4. 获取已打开的网页对象指令的优势
获取已打开的网页对象指令提供了在多标签页浏览器环境中灵活操作已打开网页的能力,具有以下几个优势:
- 灵活性强: 可以根据标题、网址等多种方式匹配网页,满足不同任务需求。
- 减少重复打开网页: 通过获取已经打开的网页对象,避免重复打开相同页面,提升任务效率。
- 适应多浏览器环境: 支持主流浏览器,如八爪鱼浏览器、谷歌浏览器、Edge浏览器,适应性强。
5. 我的使用体验
在实际任务中,获取已打开的网页对象指令帮助我有效管理和操作多个网页标签页。在一些复杂的流程中,任务会涉及多个网页,当需要处理新打开的页面时,这个指令让我能够轻松获取新页面的对象,并快速进行后续操作。它大大提高了任务的灵活性和操作效率。
最后嘛,我觉得获取已打开的网页对象指令是自动化任务中管理和操作网页的得力工具。无论是处理新打开的网页,还是管理多个浏览器标签页,它都能为你提供高效、灵活的解决方案。如果你需要操作已打开的网页对象,这个指令绝对是你的得力助手!



反爬虫抓取,人机验证,请输入验证码查看内容
请关注本站公众号回复关键字:“2024”,获取验证码。
微信搜索公众号:“RPA编程教程”或者“rpa1499” 或微信扫描上方二维码关注微信公众号



 RSS
RSS